最近在GPU编译器测试方面遇到一些瓶颈,准备学习下cuda 相关的基础知识。
之前写了一篇关于cuda的kernel函数调用相关的知识,以及一个hello world入手学习语法等。知道了GPU架构,如何写一个cuda程序,今天继续深入学习cuda的内存相关知识。
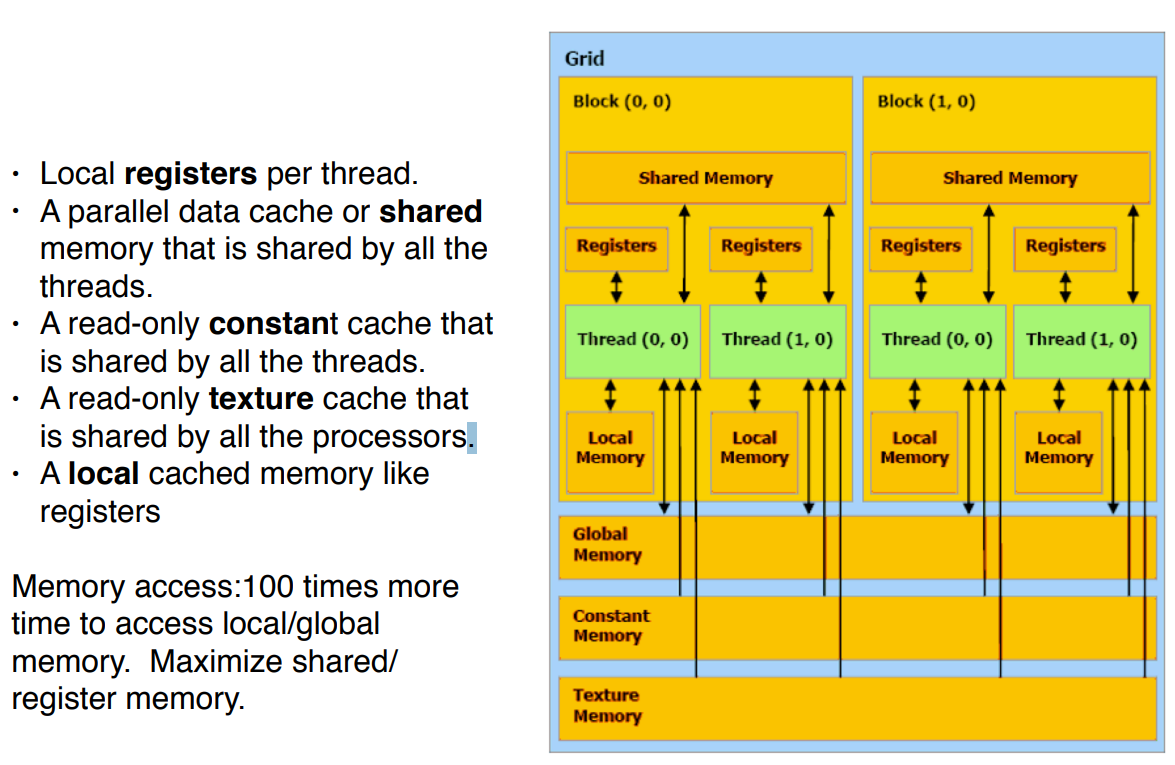
回顾下,前面学习了的内存类型:三种内存,寄存器,全局、局部内存。寄存器可用于本地存储数据,避免重复内存操作。全局内存是主存空间,用于host和 GPU 之间的数据共享。本地内存是一种特殊类型的内存,可用于存储寄存器中不适合的数据,并且是线程的私有数据,局部的。
内存分类
大致可以分为:Registers、global 、shared 、constant、local, 那就开始学习吧.
share 共享
虽然让不同的线程对不同的数据执行相同的操作是使用 GPU 的好的模式,但在某些情况下,线程需要进行通信。这种通信可能是必要的,因为我们试图实现的算法的工作方式,或者它可能来源于我们试图实现的性能目标。
掌握这些有非常大的好处,前段时间听组内的x博士讲到,比如CUDA用软件实现的算法,比amd用硬件实现的算法都要快,估计问题就在这里吧。
共享内存是线程块中所有线程共享的 CUDA 内存空间。在这种情况下,共享意味着一个线程块中的所有线程都可以对块分配的共享内存进行写入和读取,并且对这个内存的所有更改最终都将对该块中的所有线程可用。
为了在共享内存中分配一个数组,我们需要在定义前加上标识符 __share__。
extern "C"
__global__ void vector_add(const float * A, const float * B, float * C, const int size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
__shared__ float temp[3];
if ( item < size )
{
temp[0] = A[item];
temp[1] = B[item];
temp[2] = temp[0] + temp[1];
C[item] = temp[2];
}
}
上面的代码,若要为临时数组使用共享内存,请将标识符 __share__ 添加到其定义中。
虽然语法正确,但上面的示例在功能上是错误的。原因是临时数组不再是分配它的线程的私有数组,而是现在由整个线程块共享。
猜一下大概是因为是?
GPU是多个warp同时执行同一个命令,所以结果是不确定的,而且肯定不同于以前版本的 Vector_add。线程将相互覆盖对方的临时值,并且不能保证每个线程对哪个值可见。
为了修复前一个kernel,我们应该为每个线程分配足够的共享内存来存储三个值,这样每个线程都有自己的共享内存数组部分。
为了分配足够的内存,我们需要用其他内存来替换 shared float temp[3] 。如果我们知道每个线程块有1024个线程,我们可以编写如下代码:
__shared__ float temp[3 * 1024];
但是根据经验,我们知道在代码中包含常量不是一个可维护的解决方案。问题是,如果我们想声明一个共享内存数组,我们需要一个常量值,因为编译器需要知道要分配多少内存。
这个问题的解决方案是不指定数组的大小,而是将内存分配到其他地方。
extern shared float temp[];
通过将命名参数 shared_mem 添加到kernel调用来完成。修改过的代码大概是这个样子:
__global__ void vector_add(const float * A, const float * B, float * C, const int size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
int offset = threadIdx.x * 3;
extern __shared__ float temp[];
float *tmp = (float*)temp;
if ( item < size )
{
tmp[offset + 0] = A[item];
tmp[offset + 1] = B[item];
tmp[offset + 2] = tmp[offset + 0] + tmp[offset + 1];
C[item] = tmp[offset + 2];
}
}
上面的代码现在是正确的,虽然它仍然不是很有用。我们确实在使用共享内存,而且我们正在以正确的方式使用它,但是这样做并没有获得任何性能提升。实际上,我们正在使代码变得更慢,而不是更快,因为共享内存比寄存器慢。
GPU 是一个高度并行的device,可以同时执行多个线程。在前面的代码中,不同的线程可能同时更新相同的输出项,从而产生错误的结果。
为了解决这个问题,我们需要使用 CUDA 库中名为 atomicAdd 的函数。这个函数确保 output 的增量以原子方式发生,以便在多个线程想要同时更新同一项时不会发生冲突。
__global__ void histogram(const int * input, int * output)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
atomicAdd(&(output[input[item]]), 1);
}
说实话,我看完共享内存目前就知道了,共享意味着一个线程块中的所有线程都可以对块分配的共享内存进行写入和读取。关于怎么用,如何用才能写出更高效,有性能的kernel函数,我还是有一点懵。
下面来了,围绕cuda histogram函数 和atomicAdd 来完成。
histogram 函数、__syncthreads()
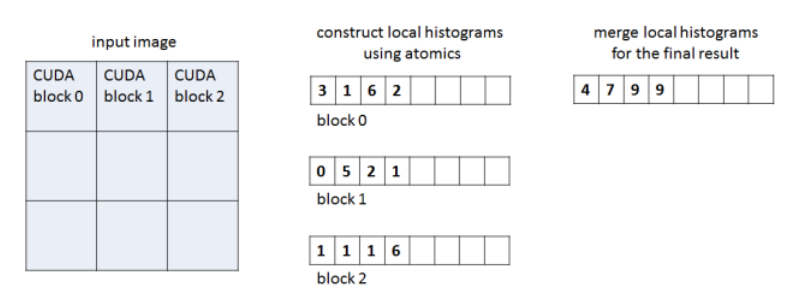
histogram 是图像处理和数据挖掘中常用的分析工具。它们显示每个数据元素出现的频率。虽然在 CPU 上计算很简单,但是传统上histogram在 GPU 上很难有效地计算。之前提出的方法包括使用遮挡查询机制(需要为每个直方图桶提供渲染通道) ,或者对图像的像素进行排序,然后搜索每个桶的开始,这两种方法都非常昂贵。我们可以使用 CUDA 和共享内存有效地生成 histogram ,然后可以将其读回host或保存在 GPU 上供以后使用。
所以用一个 CUDA histogram 函数来实现,使用共享内存来减少全局内存中的冲突。继续共享
__global__ void histogram(const int * input, int * output)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
__shared__ int temp_histogram[256];
atomicAdd(&(temp_histogram[input[item]]), 1);
atomicAdd(&(output[threadIdx.x]), temp_histogram[threadIdx.x]);
}
atomicAdd 可用于全局内存和共享内存。
CUDA的原子操作可以理解为对一个变量进行“读取-修改-写入”这三个操作的一个最小单位的执行过程,这个执行过程不能够再分解为更小的部分,在它执行过程中,不允许其他并行线程对该变量进行读取和写入的操作。基于这个机制,原子操作实现了对在多个线程间共享的变量的互斥保护,确保任何一次对变量的操作的结果的正确性。
原子操作确保了在多个并行线程间共享的内存的读写保护,每次只能有一个线程对该变量进行读写操作,一个线程对该变量操作的时候,其他线程如果也要操作该变量,只能等待前一线程执行完成。原子操作确保了安全,代价是牺牲了性能
atomicAdd(&(temp_histogram[input[item]]), 1),这句代码,每个线程根据输入的值更新共享内存中的一个任意位置,而下一行atomicAdd,每个线程读取共享内存中与其线程 ID 对应的元素。但是,对共享内存的更改不会自动对所有其他线程可用,因此最终结果可能不正确。
为了解决这个问题,我们需要同步一个块中的所有线程,以便内存操作也最终完成并对所有人可见。要同步块中的线程,我们使用 __syncthreads() 函数。此外,共享内存没有初始化,程序员也需要处理这个问题。因此,我们需要首先初始化 temp_histogram,等待所有线程都完成这项工作,在共享内存中执行计算,再次等待所有线程都完成,然后才更新全局数组。
完整的代码如下
__global__ void histogram(const int * input, int * output)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
__shared__ int temp_histogram[256];
// Initialize shared memory and synchronize
temp_histogram[threadIdx.x] = 0;
__syncthreads();
// Compute shared memory histogram and synchronize
atomicAdd(&(temp_histogram[input[item]]), 1);
__syncthreads();
// Update global histogram
atomicAdd(&(output[threadIdx.x]), temp_histogram[threadIdx.x]);
}
这个解决方案背后的想法是通过在共享内存中使用临时histogram来减少全局内存中代价高昂的冲突。当一个块处理完其输入数组的分数,并填充了局部histogram后,线程协作更新全局histogram。这种解决方案不仅潜在地减少了全局内存中的冲突,而且还产生了更好的访问模式,因为线程在第二次调用 atomicAdd 期间读取输入数组的相邻项,并写入输出数组的相邻元素。
const 内存
device侧的const值也分多种,比如inline const,literal const,immediately number。
constant Memory对于device来说只读但是对于host是可读可写,其内容可以广播到一个块中的多个线程。分配到常量内存中的变量需要在 CUDA 中使用特殊的 constant 标识符进行声明,而且它必须是一个全局变量,也就是说,它必须在包含kernel的作用域中声明,而不是在kernel本身内部声明。
代码时间:
extern "C" {
#define BLOCKS 2
__constant__ float factors[BLOCKS];
__global__ void sum_and_multiply(const float * A, const float * B, float * C, const int size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
C[item] = (A[item] + B[item]) * factors[blockIdx.x];
}
}
前面的__constant__ 就是 const memory,const内存的初始化发生在host端,不是device GPU端。
总结
共享内存比全局内存和本地内存快,共享内存可以用作用户控制的缓存来加速代码。如果在线程内部分配,则在编译时必须知道共享内存数组的大小,可以在kernel调用期间声明extern共享内存数组并传递大小。
使用 shared 在共享内存空间中分配内存,使用 __syncthreads() 等待共享内存操作对块中的所有线程可见。
全局作用域的数组,其大小在编译时已知,可以使用 constant 标识符存储在const内存中。
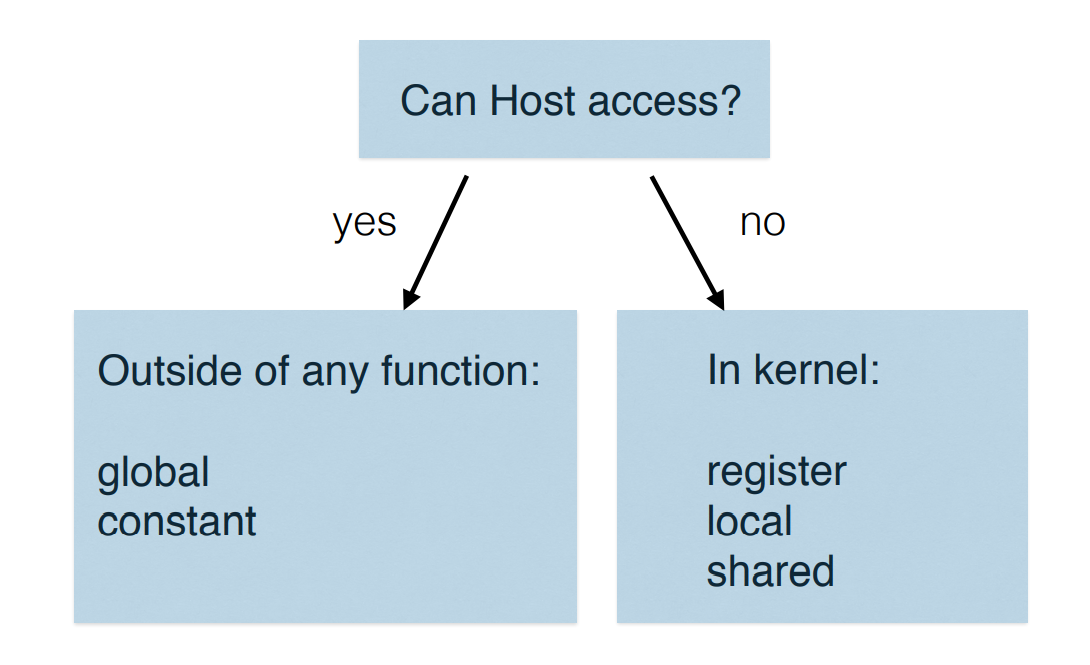
host CPU能访问分类:
对于CUDA的学习就到此告一段落了,后面用到了再来继续补充深入,学以致用,不用肯定是会忘记的,用起来吧。
推荐一个cnblogs cuda:https://www.cnblogs.com/1024incn/tag/CUDA/
Read more
http://developer.download.nvidia.com/compute/cuda/1.1-Beta/x86_website/projects/histogram64/doc/histogram.pdf
https://github.com/kevinzakka/learn-cuda/blob/master/src/histogram.cu
https://developer.nvidia.com/blog/gpu-pro-tip-fast-histograms-using-shared-atomics-maxwell/
https://carpentries-incubator.github.io/lesson-gpu-programming/06-global_local_memory/index.html
微信公众号:cdtfug, 欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。