最近在GPU编译器测试方面遇到一些瓶颈,准备学习下cuda 相关的基础知识。
之前写了一篇关于cuda的kernel函数调用相关的知识,以及一个hello world入手学习语法等。知道了GPU架构,如何写一个cuda程序,今天继续深入学习cuda的内存相关知识。
内存分类
大致可以分为:Registers、global 、shared 、constant、local, 那就开始学习吧.
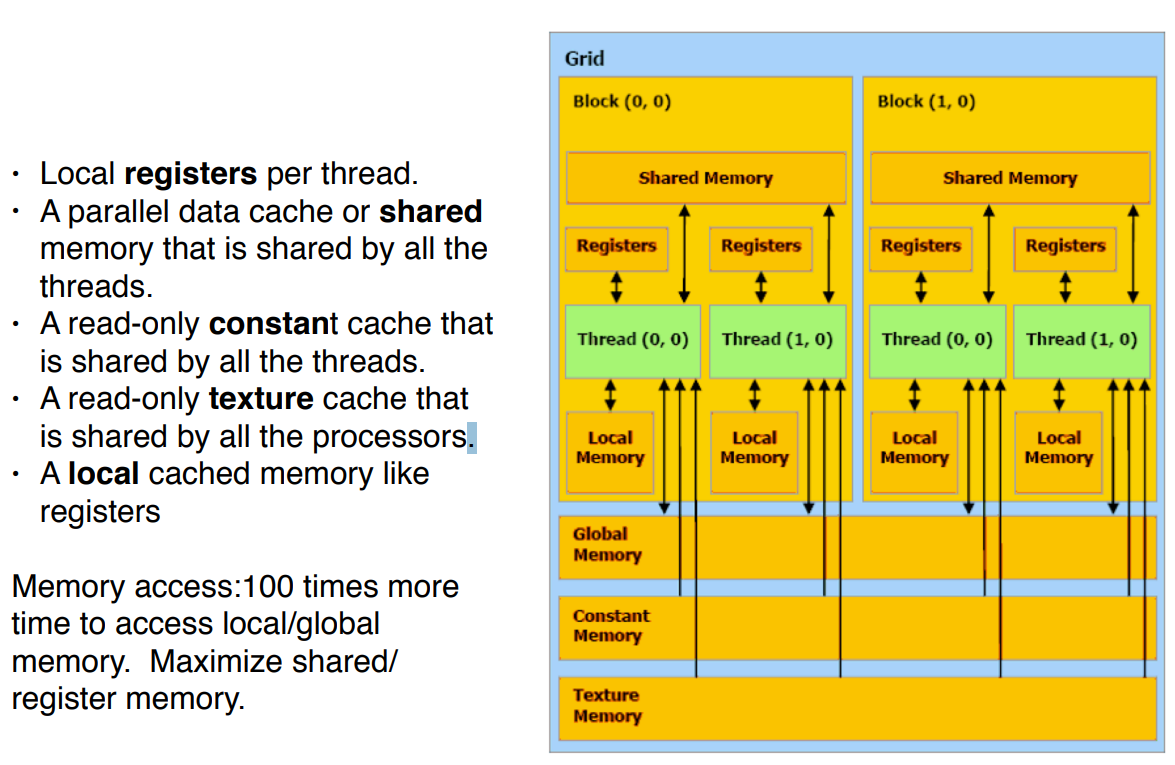
Register 寄存器
寄存器是 GPU 上最快的存储器,因此使用它们来增加数据重用是一个重要的性能优化。
如果前面看过我,学习在c里面直接使用inlineasm内联汇编,就知道大概知道如何使用寄存器,不知道也没有关系,今天来从 scratch (顺便问下,从0开始学习,这个单词合适么)学习。
GPU寄存器大概分为2类:状态类型、Mode类型,前者只能读,不能写,后者可读可写。
比如我们的mode类型寄存器分为2种,一个是处理scalar的Register, 还有一种估计猜到了,就是处理vector的 Register。
我理解的对于这种异构的GPU为了性能就是这么设计的,寄存器里面还有很多关于各种mask来达到类似if…else这种效果。
前不久学习了指令汇编,后面可以继续抛砖引玉,类似把一段010101010 转成mov r0, r1,这个非常有趣。
寄存器是chip上的快速存储器,用于存储由计算核心执行的操作的操作数。
在helloworld中,使用的 Vector_add 代码中就有寄存器。通常,CUDA 代码中定义的所有标量变量都存储在寄存器中。
寄存器是一个线程的本地寄存器,每个线程都对自己的寄存器有独占访问权: 寄存器中的值不能被其他线程访问,甚至不能从同一块访问,也不能被host访问。寄存器也不是永久的,因此存储在寄存器中的数据只有在线程执行期间才可用。
问题:下面这段code用了多少register?
extern "C"
__global__ void vector_add(const float * A, const float * B, float * C, const int size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
if ( item < size )
{
C[item] = A[item] + B[item];
}
}
通常,如果不检查编译器本身生成的输出,就不可能准确知道编译器将使用多少个寄存器。然而,我们可以基于所使用的变量粗略估计所需寄存器的数量。我们最可能需要一个寄存器来存储变量 item,两个寄存器来存储 A[item]和 B[item]的内容,另外一个寄存器来存储和 A[item] + B[item]。因此,Vector_add 可能使用的寄存器数量是4。
Vector_add 中,我们显式地声明了三个浮点变量来存储从内存加载的值和我们的输入项的和,这使得对用过的寄存器的估计更加明显。
if ( item < size )
{
// C[item] = A[item] + B[item];
temp_a = A[item];
temp_b = B[item];
temp_c = temp_a + temp_b;
C[item] = temp_c;
}
在我们的示例中,这是完全没有必要的,因为编译器将自行决定为每个线程分配多少寄存器,以及在这些寄存器中存储什么内容。但是,显式的寄存器使用对于重用已经从内存加载的,非常重要。
Global 全局
全局内存可以看作是 CUDA 中 GPU 的主要空间。它由host分配和管理,host和 GPU 都可以访问它,因此可以使用全局内存空间在两者之间交换数据。它是可用的最大内存空间,因此它可以比寄存器包含更多的数据,但是访问速度也更慢。此内存空间不需要任何特殊的内存空间标识符。
extern "C"
__global__ void vector_add(const float * A, const float * B, float * C, const int size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
if ( item < size )
{
C[item] = A[item] + B[item];
}
}
向量 A、 B 和 C 存储在全局内存中。
上面这段代码很明显就是直接从host,copy过来的数据,这个就是全局内存。
默认情况下,在host上分配并作为参数传递给kernel的内存是在全局内存中分配的。
所有线程、所有线程块都可以访问全局内存。这意味着线程可以读写全局内存中的任何值。
虽然全局内存对于所有线程都是可见的,但是请记住,全局内存是不一致的,并且在kernel执行期间,由一个线程块所做的更改可能不可用于其他线程块。但是,所有内存操作都在kernel终止时完成。
Local 本地、局部
内存也可以从kernel中静态分配,根据 CUDA 编程模型,这样的内存将不是全局的,而是局部的内存。本地内存只能由分配它的线程可见,因此只有自己可以访问。因此,执行kernel的所有线程都将拥有自己私有分配的本地内存。
extern "C"
__global__ void vector_add(const float * A, const float * B, float * C, const int size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
if ( item < size )
{
C[item] = A[item] + B[item];
}
}
看上面的参数是带有const的,区别就在这里。我们需要将本地数组的大小作为一个新参数传递给kernel。
比如下面的代码,代码中指定数组大小为3,编译器将分配寄存器而不是本地内存。
extern "C"
__global__ void vector_add(const float * A, const float * B, float * C, const int size, const int local_memory_size)
{
int item = (blockIdx.x * blockDim.x) + threadIdx.x;
float local_memory[local_memory_size];
if ( item < size )
{
local_memory[0] = A[item];
local_memory[1] = B[item];
local_memory[2] = local_memory[0] + local_memory[1];
C[item] = local_memory[2];
}
}
可以修改host代码,添加一行代码并更改调用kernel的方式。
直接在host侧,int local_memory_size=3,这样就可以修改了。
本地内存不是一个特别快的内存,实际上它具有类似的吞吐量和全局内存的延迟,但是它比寄存器大得多。
例如,CUDA 编译器会自动使用本地内存来存储溢出的寄存器,也就是说,暂时存储因为寄存器文件中没有足够的空间而不能再保存在寄存器中的变量,但这些变量将来会再次使用,因此不能被擦除。
总结
今天大概学习了三种内存,寄存器,全局、局部内存。寄存器可用于本地存储数据,避免重复内存操作。全局内存是主存空间,用于host和 GPU 之间的数据共享。本地内存是一种特殊类型的内存,可用于存储寄存器中不适合的数据,并且是线程的私有数据,局部的。
文章太长不利于一次性看完,没有成就感。下一篇继续学习share memory之类的。
Read more
https://carpentries-incubator.github.io/lesson-gpu-programming/06-global_local_memory/index.html
https://www.ce.jhu.edu/dalrymple/classes/602/Class13.pdf
https://www.cnblogs.com/maomaozi/p/16175725.html
微信公众号:cdtfug, 欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。