最近在GPU编译器测试方面遇到一些瓶颈,准备学习下cuda 相关的基础知识。
之前写了一篇关于cuda的kernel函数调用相关的知识,今天再来从一个hello world入手学习。
cuda kernel定义
普通函数和CUDA程序的区别。
void CPUFunction()
{
printf("This function is defined to run on the CPU.\n");
}
__global__ void GPUFunction()
{
printf("This function is defined to run on the GPU.\n");
}
int main()
{
CPUFunction();
GPUFunction<<<1, 1>>>();
cudaDeviceSynchronize();
}
其中,__global__ void GPUFunction() 被称作核函数(kernel function),是cuda核心程序的入口部分。程序执行至这里时,将代码段交由GPU执行。
注意要加上 __global__ 关键字,表示这是运行在GPU上的函数。
核函数在调用时,使用三对尖括号,里面的两个变量分别对应block数量与thread数量,引出下面的内容。
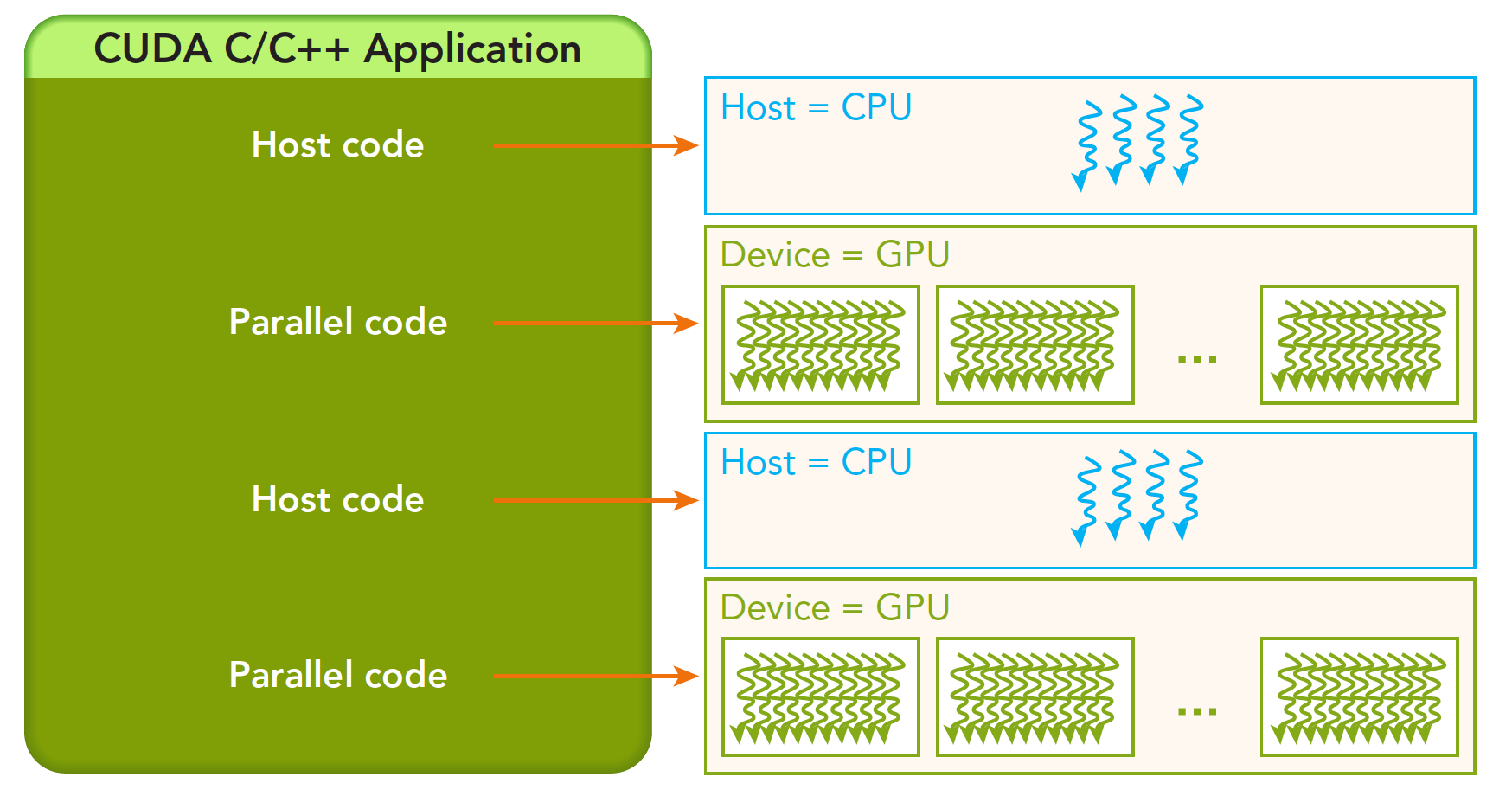
kernel对应就是在device运行,CPU侧就是在host上运行,还有一个就device上调用,device上执行。

cuda 编程
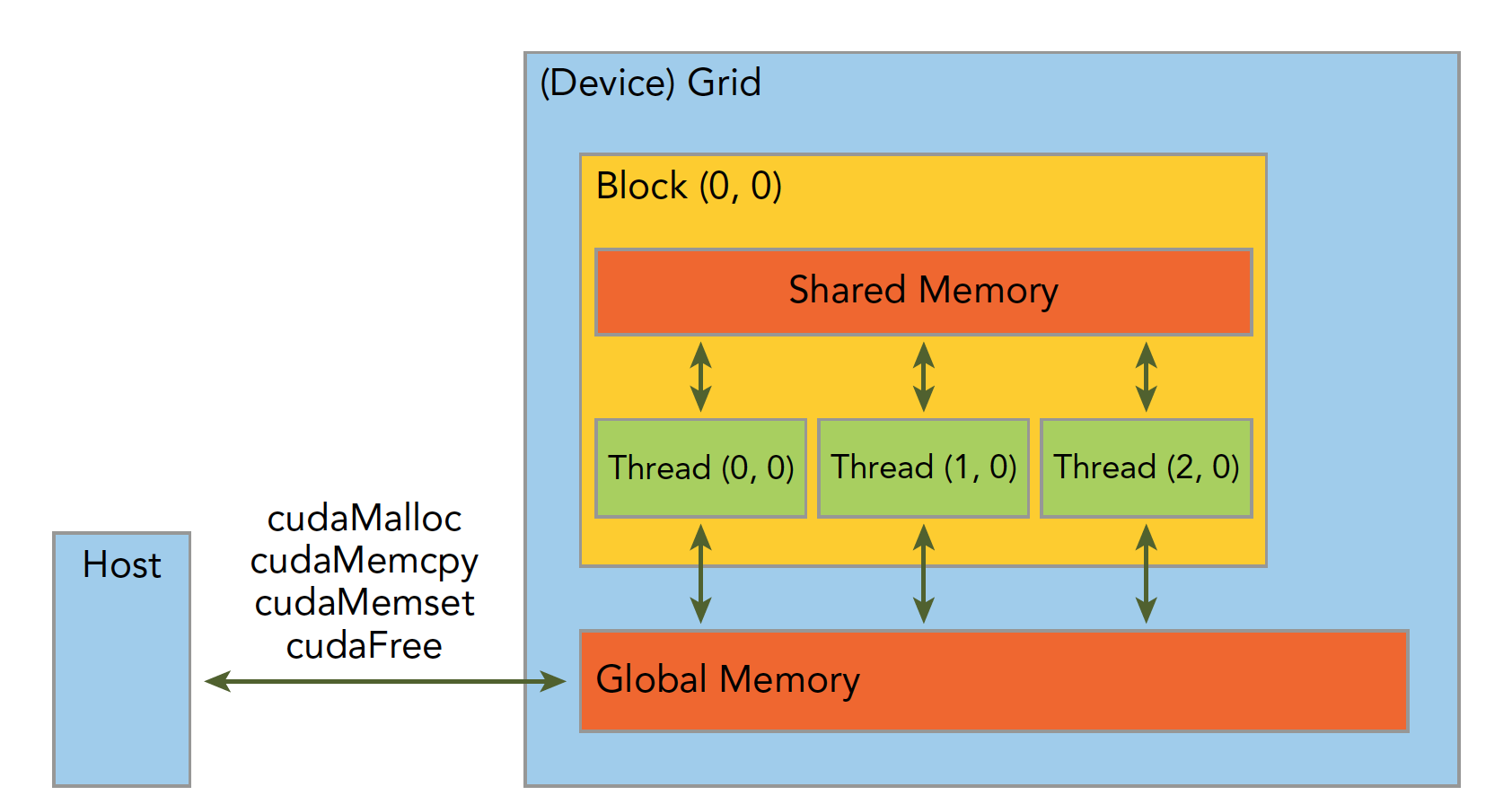
一个异构环境,通常有多个CPU多个GPU,他们都通过PCIe总线相互通信,也是通过PCIe总线分隔开的。所以我们要区分一下两种设备的内存:
主机:CPU及其内存 设备:GPU及其内存
内存管理
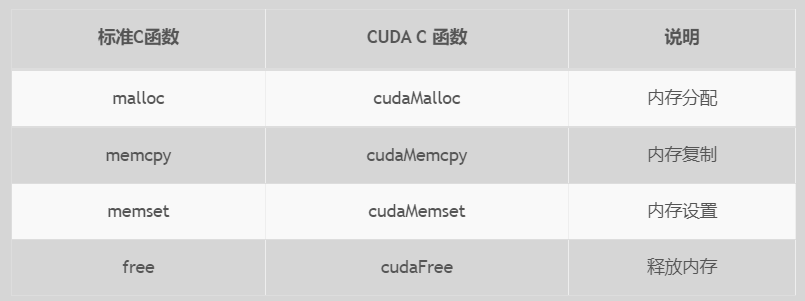
内存管理在传统串行程序是非常常见的,寄存器空间,栈空间内的内存由机器自己管理,堆空间由用户控制分配和释放,CUDA程序同样,只是CUDA提供的API可以分配管理设备上的内存,当然也可以用CDUA管理主机上的内存,主机上的传统标准库也能完成主机内存管理。 下面表格有一些主机API和CUDA C的API的对比:
除了nv的,还有amd的hip也了解下。似乎就是吧cuda换成hip,你看这多方便开发者,基本上无缝切换~
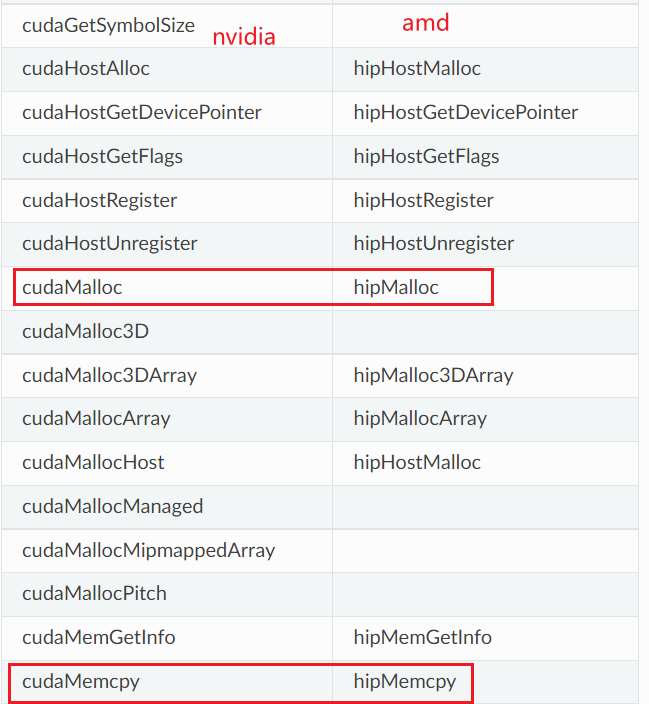
其他参考这个页面:https://sep5.readthedocs.io/en/latest/Programming_Guides/CUDAAPIHIPTEXTURE.html
这个函数是内存拷贝过程,可以完成以下几种过程(cudaMemcpyKind kind),右边是对比的amd hip编程。
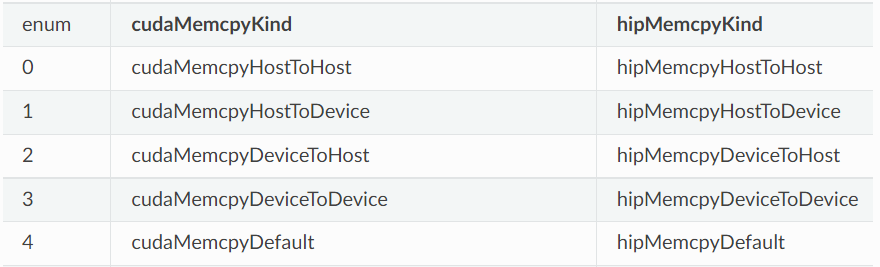
就是字面意思,memory copy xx to yy。
我自己有几点经验或者是自己踩坑的总结;
- 内存拷贝: 分配的大小一定要一致
- 初始化:要cpy到device值
- 指针,和这个太基础了,但是我经常犯错
- 数据大小,根据thread和元素大小来决定,避免数据安全问题
#include <cuda_runtime.h>
__global__ void kernel(float*dst,float*src)
{
……
}
int main()
{
……
CHECK(cudaMalloc((float**)&d_out,nByte));
CHECK(cudaMalloc((float**)&d_in,nByte));
……
cudaMemcpy(d_in,h_in,nByte,cudaMemcpyHostToDevice);
kernel<<<grid,block>>>(d_out,d_in);
cudaMemcpy(h_out,d_out,nByte,cudaMemcpyDeviceToHost);
// use h_out from GPU
cudaFree(d_out);
cudaFree(d_in);
return 0;
}
block和thread的配置
一个BLOCK不能分到多个SM上执行,但是不同的Block有可能会分到相同的SM(这个是调度器控制的,对用户不可见)。既然sharedmemory在sm上,这样就解释了为什么Block之间没有办法共享shared memory,也不能够进行同步,否则会产生死锁。
上面的helloworld程度段只包含了一个核函数,运行的时候
GPUFunction«<1, 1»>();
这个核函数内只有一个block,每个block内1个thread。运行一次就完成了。
GPUFunction«<10, 1»() 配置为在 10 个线程块(每个均具有单线程)中运行后,将运行 10 次。 GPUFunction«<1, 10»() 配置为在具有 10 线程的单个线程块中运行后,将运行 10 次。 GPUFunction«<10, 10»() 配置为在 10 个线程块(每个均具有 10 线程)中运行后,将运行 100 次。
基可以用threadIdx.x 和blockIdx.x 来组合获得对应的线程的唯一标识,hreadIdx和blockIdx能组合出很多不一样的效果。
compiler
CUDA在编译时使用编译器nvcc,作为一个C的扩展,nvcc的编译方法和gcc/g++类似。
NvCC 将这两部分分开, 并将主机代码(将在 CPU 上运行的代码部分)发送给像 gcc 或者 Intel C++编译器(ICC)或者微软 Visual c++ Compiler 这样的 C 编译器, 然后将 device 代码(将在 GPU 上运行的部分)发送给 GPU。device代码由 NVCC 进一步编译。NVCC 是基于 LLVM 的。根据 Nvidia 提供的文档,7.0版本中的 nvcc 支持许多由 C++ 11标准定义的语言结构和一些 C99特性。在版本9.0中,支持来自 C++ 14标准的多个构造。
CUDA 语言扩展的源文件(.cu)必须用 nvcc 编译。NVCC 是一个编译器驱动程序,它通过调用所有必要的工具和编译器来工作,比如 cudacc、 g++ 、 cl 等。NVCC 可以输出 C 代码(CPU 代码) ,然后必须使用另一个工具或 PTX 或对象代码直接与应用程序的其余部分一起编译。一个具有 CUDA 代码的可执行文件需要: CUDA 核心库和 CUDA 运行库。
类似cudacc编译这部分目前就是我们正在做的,可以参考llvm编译器框架。
调用
除了用<<<>>>来调用kernel函数,这个三个尖括号<<<grid,block>>>内是对设备代码执行的线程结构的配置(或者简称为对内核进行配置),也就是我们上一篇中提到的线程结构中的grid,块还可以使用。
cudaLaunchKernel ( const void* func, dim3 gridDim, dim3 blockDim, void** args, size_t sharedMem, cudaStream_t stream )
上面的等于cudaLaunchKernel(GPUFunction, 1, 1, 0, 0)。
CPU和GPU是异步执行的,所以执行完了要看到print打印信息,需要sync才可以看到。
要注意的地方就是gridDim、blockDim、以及shareMem,比如在访问shareMemory的时候,一定要指定这个大小,不然同步回来的结果可能是0.
Read more
https://sep5.readthedocs.io/en/latest/Programming_Guides/CUDAAPIHIPTEXTURE.html
https://docs.nvidia.com/cuda/cuda-runtime-api/group__CUDART__EXECUTION.html
https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html
https://www.cnblogs.com/maomaozi/p/15939275.html
微信公众号:cdtfug, 欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。