最近在GPU编译器测试方面遇到一些瓶颈,准备学习下cuda 相关的基础知识。
warp/sm/index/grid等。
CPU VS GPU
GPU最重要的一点是可以并行的实现数据处理。
这一点在数据量大、运算复杂度不高的条件下极为适用。可以简单地把一块GPU想象成一个超多核的CPU运算部件。这些CPU有自己的寄存器,还有供数据交换用的共享内存、缓存,同时周围还有取指部件和相应的调度机制,保证指令能够在之上执行。
这里有一张典型的CPU和GPU的对比图片,CPU和GPU就呈现出非常不同的架构
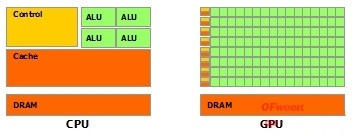
- 鲜绿色:计算单元ALU(Arithmetic Logic Unit)
- 橙红色:存储单元(cache)
- 橙黄色:控制单元(control)
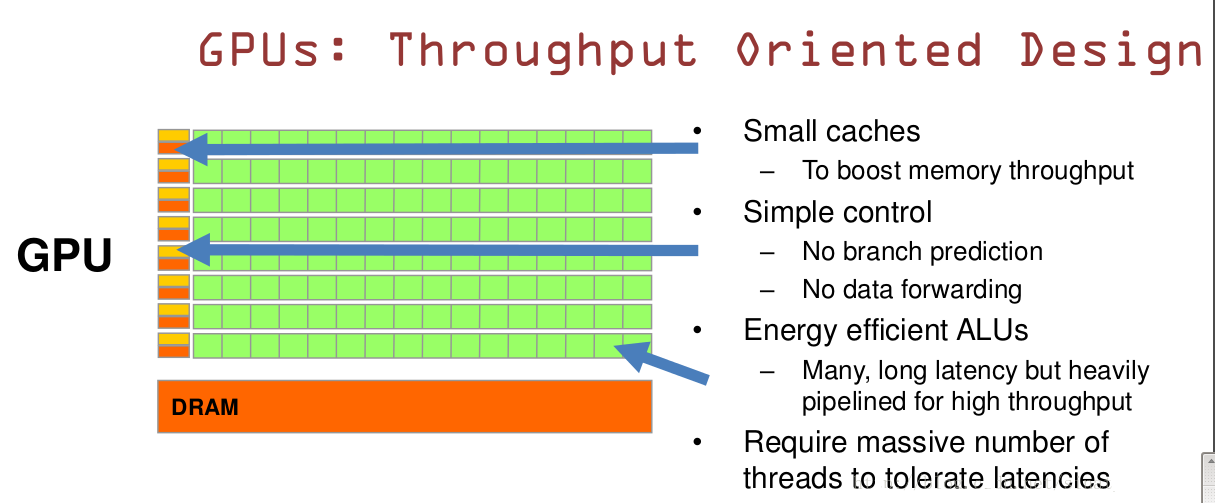
GPU:数量众多的计算单元和超长的流水线,只有简单的控制逻辑并省去了Cache CPU:被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路。
这个比喻就很恰当:
GPU的工作大部分就是这样,计算量大,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分
CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个
CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别,而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了。
软件
grid 概念
CUDA 采用异构编程模型,用于运行主机设备应用程序。它有一个类似于 OpenCL 的执行模型。在这个模型中,我们开始在主机设备上执行一个应用程序,这个设备通常是 CPU 核心。该设备是一个面向吞吐量的设备,也就是说,一个 GPU 核心执行并行计算。内核函数用于执行这些并行执行。一旦执行了这些内核函数,控制就被传递回继续执行串行操作的主机设备。
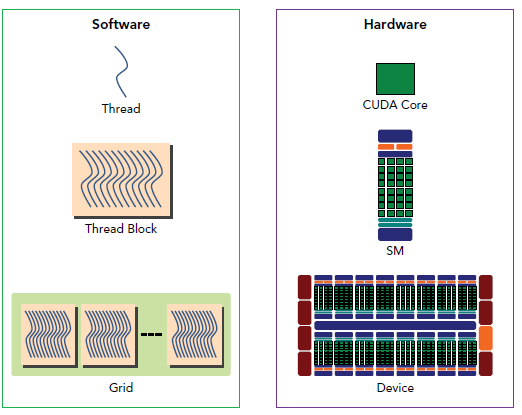
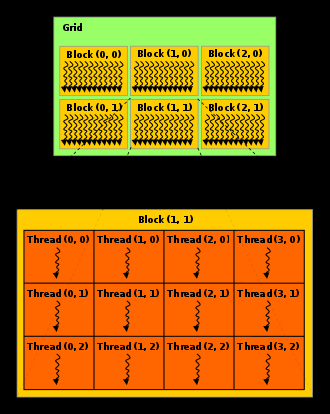
为了方便定位threadidx等,用多维数据来表示,就有了维度。
由于许多并行应用程序涉及多维数据,因此可以很方便地将线程块组织成一维、二维或三维线程数组。grid中的块必须能够独立执行,因为grid中的块之间不可能进行通信或合作。当启动一个内核时,每个线程块的线程数量,并且指定了线程块的数量,这反过来又定义了所启动的 CUDA 线程的总数。
块的最大 x、 y 和 z 维分别为1024、1024和64,其分配应使 x × y × z ≤1024,即每个块的最大线程数。
扩展理解:float4, int4, long4 又是什么?有什么好处?
index 索引
CUDA 中的每个线程都与一个特定的索引相关联,因此它可以计算和访问数组中的内存位置。
举个例子:
其中有一个512个元素的数组。其中一种组织结构是使用一个包含512个线程的单个块的grid。假设有一个由512个元素组成的数组 C,它由两个数组 A 和 B 的元素相乘构成,这两个数组都是512个元素。每个线程都有一个索引 i,它执行 A 和 B 的第 i 个元素的乘法运算,然后将结果存储在 C 的第 i 个元素中。 i 是通过使用 blockIdx (在这种情况下是0,因为只有一个块)、 blockDim (在这种情况下是512,因为块有512个元素)和 threadIdx 计算得到的,每个块的值从0到511不等。
线程索引 i 按以下公式计算:
int i = blockIdx.x * blockDim.x + threadIdx.x;
因此,i的值范围从0到511,覆盖整个数组。但是不一定是连续的,3,4,1,2。。。。
再来:
考虑一个大于1024的数组的计算,我们可以有多个块,每个块有1024个线程。考虑一个包含2048个数组元素的示例。在这种情况下,我们有2个线程块,每个线程有1024个线程。因此线程标识符的值将从0到1023不等,块标识符将从0到1不等,块维度将为1024。因此,第一个块将获得从0到1023的索引值,最后一个块将获得从1024到2047的索引值。
每个线程将首先计算它必须访问的内存索引,然后继续进行计算。举个实际的例子,其中数组 A 和 B 的元素通过使用线程并行添加,结果存储在数组 C 中。线程中相应的代码如下所示
__global__ void vectorAdd (float *A , float *B , float * C , int n)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < n)
{
C[index] = A[index] + B[index] ;
}
}
除了一维还有2/3维度,计算index可以参考公式,也是一样不一定连续, 234,235,200,201……
硬件
SM stream Multiprocessor: 流多处理器
每个SM内又包括了多个SP(streaming processor)。而SP正是实现算数功能的核心部件,可以类比CPU之中的ALU单元,只不过其计算能力要差很多。
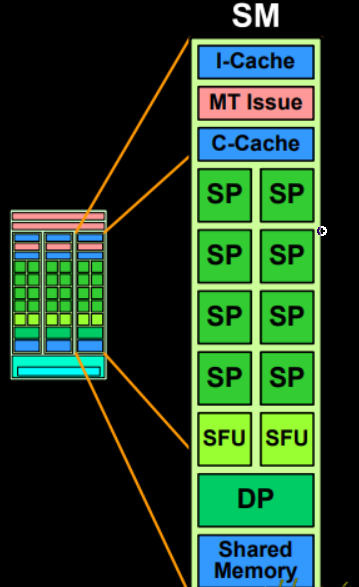
可以看到,每个SM内部的SP之间,可以共享一块shared memory。
以及一块指令缓存用于存放指令、一块常量缓存(c-cache)用来存放常量数据,两个SFU(特殊运算单元,special function unit)用来做三角函数等较复杂运算,MT issue用来实现多线程下的取指,以及DP(Double Precision Unit)用来做双精度数。 除去一些运算单元之外,最重要的就是c-cache与shared memory两块数据存储区。注意这两个位置的数据只能由SM内部的SP进行访问,SM之间也有用于数据交换的区域。最主要的是global memory。
硬件将线程块调度到一个 SM。一般来说,SM 可以同时处理多个线程块。一个 SM 可能总共包含多达8个线程块。线程 ID 由其各自的 SM 分配给线程。
每当 SM 执行一个线程块时,线程块中的所有线程都同时执行。因此,为了释放 SM 内部线程块的内存,关键是该块中的整个线程集都已结束执行。每个线程块被划分为预定的单元,称为warp。
warp (wave、wavefront)
不同GPU vendor叫法不一样,A卡叫wave,N卡叫warp/卧铺/,我司的也叫wave。我个人理解的就是一波波的相同指令的线程执行,wave好记。
Warp:warp是SM调度和执行的基础概念,通常一个SM中的SP(thread)会分成几个warp(也就是SP在SM中是进行分组的,物理上进行的分组),一般每一个WARP中有32个thread.这个WARP中的32个thread(sp)是一起工作的,执行相同的指令,如果没有这么多thread需要工作,那么这个WARP中的一些thread(sp)是不工作的,叫inactive。
我们应该注意,线程、线程块和grid本质上是编程的视角。为了得到一个完整的线程块要点,从硬件的角度了解它是至关重要的。硬件将执行相同指令的线程分组为 warps 。几个warps组成一个线程块。几个线程块被分配给一个流式多处理器(SM)。几个 SM 组成了整个 GPU 单元(执行整个内核grid)。
编程的视角与 GPU 中线程块的硬件视角之间的图形关联。
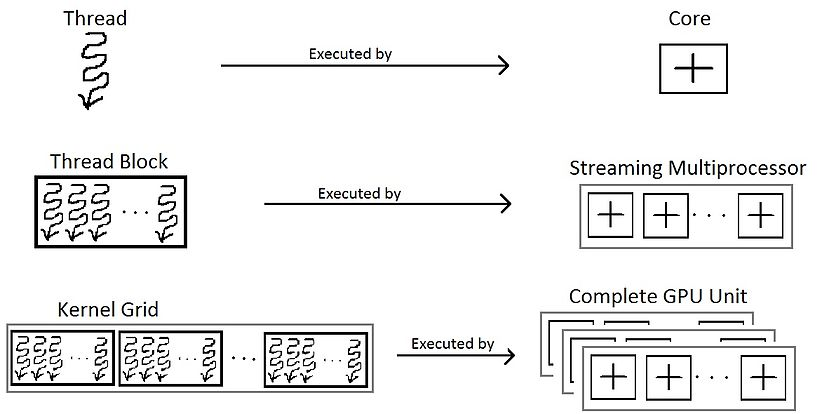
在硬件方面,线程块由“warp”组成。warp是一个线程块中的32个线程的集合,使得warp中的所有线程执行相同的指令。这些线程由 SM 连续选择。
假设有32个执行指令的线程。如果其中一个或两个操作数都没有准备好(例如还没有从全局内存中获取) ,就会发生一个称为“上下文切换”的过程,将控制权转移到另一个指定的操作数上。
当从一个特定的warp切换时,warp的所有数据都保留在寄存器文件中,以便在其操作数准备就绪时能够迅速恢复。当一条指令没有突出的数据依赖关系时,也就是说,它的两个操作数都准备好了,就认为各自的偏差已经准备好可以执行了。如果有多个warp符合执行条件,则父 SM 使用一个warp调度策略来决定哪个warp获取下一个提取指令。
warp调度有不同的策略,这个有点深入,先不看,加个#TODO。比如RR、LRF、FAIR、CAWS。
Read more
https://en.wikipedia.org/wiki/Thread_block_(CUDA_programming)
https://www.nvidia.com/content/PDF/fermi_white_papers/NVIDIA_Fermi_Compute_Architecture_Whitepaper.pdf
http://www.uml.org.cn/embeded/201809034.asp?artid=21130
https://www.cnblogs.com/maomaozi/p/15939275.html
微信公众号:cdtfug, 欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。