SIMT 是什么意思?
Single Instruction Multiple Threads” (SIMT) 单指令多线程。
在纯 SIMD 中,一条指令以完全相同的方式作用于所有数据。
在 SIMT 中,这一限制有所放松:可以激活或停用选定的线程,以便仅在活动线程上处理指令和数据,而在非活动线程上本地数据保持不变。
因此,SIMT 可以适应分支,尽管效率不高。给定以 if (条件) 开头的 if-else 构造,当运行 if 子句中的语句时,condition==true 的线程将处于活动状态,而当运行 else 中的语句时,condition==false 的线程将处于活动状态条款。结果应该是正确的,但非活动线程在等待活动子句中的语句完成时不会执行任何有用的工作。SIMT 内的分支如下图所示。
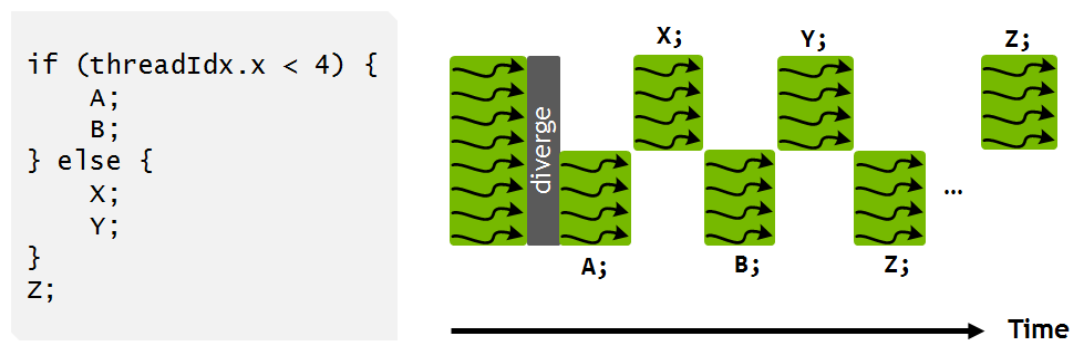
在 Volta 之前的 NVIDIA GPU 中,整个 if 子句(即语句 A 和 B)必须由相关线程执行,然后整个 else 子句(语句 X 和 Y)必须由相关线程执行其余线程,则所有线程在继续执行之前都必须同步(语句 Z)。Volta 更灵活的 SIMT 模型允许在中间点(例如 A 和 X 之后)同步共享数据。
这些不同的语句块在不同的线程里面,我们知道 GPU 都是并行运行的。那么这些线程都是执行的同一个命令,那结果怎么处理?
warp
warp 是什么意思?
指的是编织者的梭子穿过的一组垂直线-warp,为了后面更形象的理解吧。顺便说一下横着的是 weft。
在编程技术里面,是这个意思:The term warp originates from weaving, the first parallel-thread technology.
在运行时,线程块被分为多个线程束以供 SIMT 执行。一个完整的 warp 由一组具有连续线程索引的 32 个线程组成。然后,warp 中的线程由一组 32 个 CUDA 核心一起处理。这类似于 CPU 上的向量化循环被分成固定大小的向量,然后由一组向量通道进行处理的方式。
将线程捆绑为 32 个线程束的原因很简单,在 NVIDIA 的硬件中,CUDA 核心被分为固定的 32 个组。将大线程块分解成这种大小的块可以简化 SM 在其可用资源上调度整个线程块的任务。
这个图,大家应该看到很多很多次了吧。
read more
- https://cvw.cac.cornell.edu/gpu-architecture/gpu-characteristics/simt_warp