先来一个例子:
A 给 B 转账,A 负责存款,B 负责取款。比如:
- 客户 A 去银行 ATM 机前转账给 B
- 客户 B 随后也来使用 ATM 机取 A 给他转账
比如客户 B 先进行了取款,但他的钱还没有进入账户,此时如果客户 B 进行取款,他会取出的钱比实际余额少(如果取出的钱多了,记得退回去,不然是违法的哦),这就像后续指令读取了旧的数据一样。
为了解决这个问题,银行会要求客户排队取款,严格控制操作顺序。这相当于编译器重新排序指令以解决 data hazard。
如果某个客户的取款操作比较复杂,需要一定时间,则会影响后续客户的取款,此时银行可能会要求客户 B 等一会再进行操作,以缓冲时间,这就像插入 nop 指令一样。
而银行 ATM 机内部的账户余额数据可以看作是“寄存器”值,它会实时更新,那么无论外部操作多快,账户余额这个寄存器的值总是正确的最新值,这样在用户读取时就避免了 data hazard。
所以这个银行取款的例子来理解 data hazard 和解决方法。客户进行取款操作相当于指令执行,ATM 机与银行账户系统相当于 CPU 与主存,采取的排队、等待和寄存器机制都能很好说明编译器是如何处理 data hazard 的。
先来看一段指令,下面 2 个指令相当于是同时发出,只是 sub 指令比 and 指令早一个 cycle 发出:
sub $2,$1,$3
and $12,$2,$5
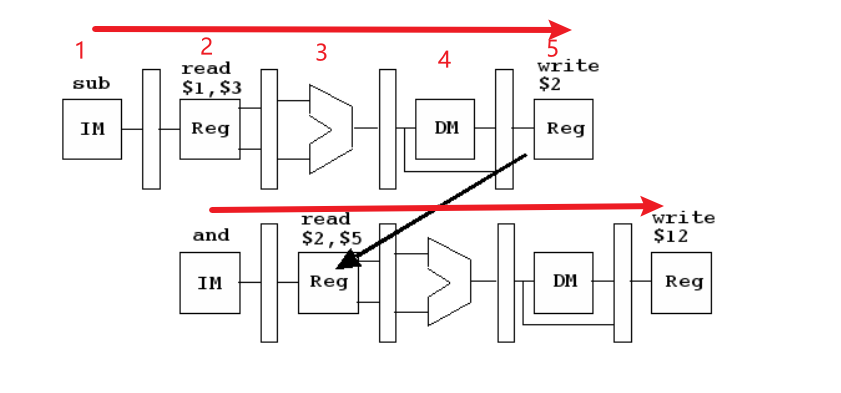 解读:
解读:
sub指令在读取寄存器 $1 和 $3,并将它们传递给 ALU,然后把结果 $2 保存到 reg 寄存器上。
and 指令在第 3 个周期读取 $2 和 $5 寄存器的数据,记得这个里面的的 $2 依赖sub的,在第 3 个周期的时候,$2 还没有更新,就出发了 data hazard,称之为数据风险。
如果一条指令读取的寄存器在未来的周期中被前一条指令覆盖,就会发生数据冲突。我们必须消除数据隐患,否则流水线会产生不正确的结果。
在 llvm 编译器里,data hazard 指的是读写同一条指令序列中相邻的指令访问同一存储器位置,并且至少有一个指令是写操作的情况。这会导致后续指令读取的是旧的数据,影响正确性。 再来一个简单的例子:
add r1, r2, r3 # r1 = r2 + r3
sub r4, r1, r5 # r4 = r1 - r5
这里有一个 data hazard,因为 sub 指令要读取 r1 的值,但是 add 指令刚刚更新了 r1,所以 sub 读取到的还是 r1 的旧值,导致计算错误。 为了解决 data hazard,编译器通常会在指令序列中插入 nop 指令或重新排列指令顺序,让存储器访问时间错开,避免读写冲突。也可以使用域霸道之类的硬件来缓存需要的寄存器值,避免直接从存储器读取。 所以在 llvm 中,解决 data hazard 的主要方法是:
- 重新排序指令
- 插入 nop 指令
- 使用寄存器重命名和寄存器缓冲来缓存值,避免频繁访问主存。
- 硬件来实现暂停
消除 data hazard
1. 插入 nop 指令
还是上面的例子,就是把读取 $2寄存器的地址的时候推迟到写之后,就可以了。
看图片
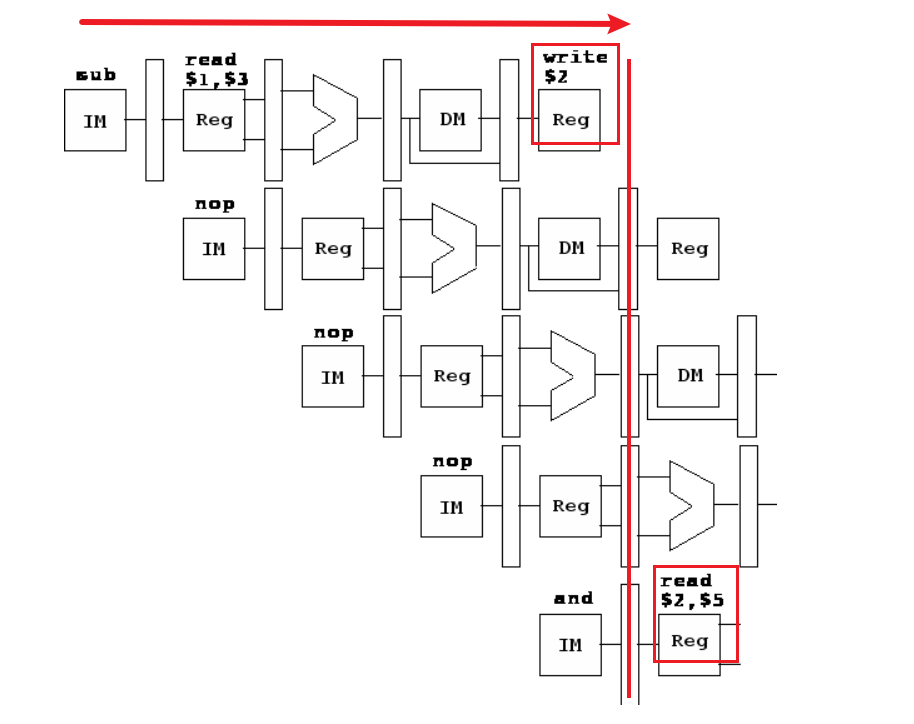
最后得到的指令为,nop 简单粗暴的理解为相当于 sleep
sub $2,$1,$3
nop
nop
nop
and $12,$2,$5
这使消除危险的责任落在了编译器编写者身上,而且不涉及额外的硬件。
2. 硬件来实现
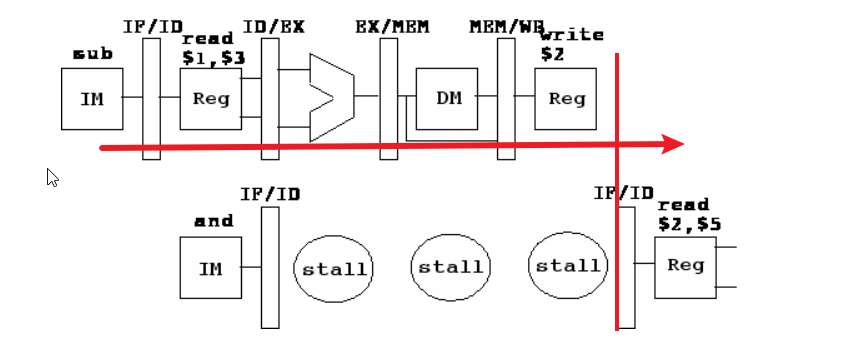
在检测到危险之后,我们停止指令内存,以便在停止问题解决之前不会读取新指令。检测危险条件包括检查每个流水线寄存器中的写寄存器。如果写入寄存器等于 IF/ID 寄存器中的两个读取寄存器中的任何一个,则会发生停顿(stall)。
3. 重新排序指令
编译器通过重新排序指令 (instruction re-ordering) 来解决 data hazard 的具体实现如下:
-
编译器会分析指令序列,检查是否存在读后写 (read after write) 的数据依赖关系,即后续指令要读取的寄存器正被前面的指令更新。如果检测到这样的数据冲突,就需要重新排序。
-
编译器会计算每个指令的最早执行时间 (earliest execution time) 和最晚执行时间 (latest execution time)。最早时间是考虑数据依赖的最快执行时间,最晚时间是考虑控制依赖和结构限制的最晚时间。只有在两个指令的时间区间有重叠,它们才能交换顺序。
-
编译器会在时间区间有重叠的指令里选择一个或多个指令进行交换,将它们重新排序到一个不会产生数据冲突的顺序。选择哪些指令交换涉及到一些优化策略。
-
编译器会通过重复 2 和 3 的步骤,尽量重新排序更多的指令,扩大重排序范围,获得最大的重排序效果。但仍需要确保重排序后程序的语义不变。
-
有些指令由于控制依赖或者结构限制无法重排序,对它们编译器将选择插入 nop 指令以避免数据冲突。
所以,编译器通过计算指令时间区间找寻重排序机会,交换能重排序的指令顺序,不断扩大重排序范围,以解决尽可能完整的数据冲突问题。为无法重排序的指令插入空 nop 指令也能起到类似效果。这就是编译器实现 data hazard 重排序的基本思想和方法。
更多阅读
微信公众号:cdtfug,欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。