什么是编译器优化
保持语义不变的情况下,对程序运行速度、程序可执行文件大小作出改进。
编译器优化(Compiler optimization)是指在编译器将源代码转化为可执行代码的过程中,通过对程序的分析和优化,使得生成的目标代码在执行速度、占用内存等方面都能够达到更好的效果。
具体来说,编译器优化可以通过减少代码的重复计算、减少缓存未命中的情况以及减少不必要的寄存器使用等方式提高程序的执行效率,从而让程序的运行更快、更稳定。同时,优化也可以使得编译出来的目标代码更加紧凑,减少程序所占用的内存和磁盘空间。
编译器优化的主要目标是提高程序的性能、优化目标代码的大小以及减少程序的资源占用。为了达到这些目标,编译器需要对源代码进行细致的分析,确定不必要的代码并去除,同时在编译过程中根据程序的表现不断进行优化调整,以逐步提高程序的性能。
我们老大叫我们多看看在 LLVM 上优化,可以参考下 GCC 的优化方法。你们有没有什么好的方法?
LTO
LTO(Link Time Optimization)是一种通过整个程序分析和跨模块优化来实现更好的运行时性能的方法。在编译阶段,clang 会发出 LLVM 位码而不是对象文件。链接器会识别这些位码文件,并在链接过程中调用 LLVM,以生成构成可执行文件的最终对象。LLVM 实现加载所有输入的比特码文件,并将它们合并在一起以产生一个单一的模块。程序间分析(IPA)和程序间优化(IPO)在这个单体模块上连续进行。
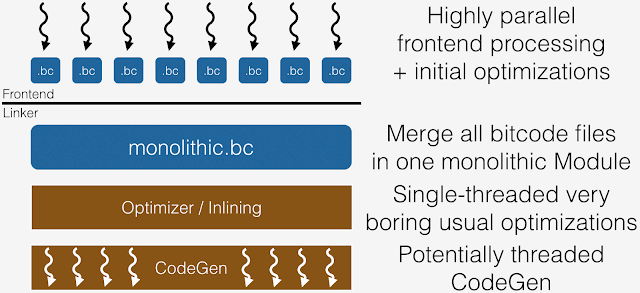
LTO 有个缺点:这在实践中意味着 LTO 经常需要大量的内存(以一次容纳所有的 IR),而且速度非常慢。而在通过-g 启用调试信息的情况下,IR 的大小和由此产生的内存需求会明显增大。即使没有调试信息,这对于非常大的应用程序,或者在内存受限的机器上进行编译,也是令人望而却步的。这也使得增量构建不那么有效,因为当任何输入源发生变化时,从 LTO 步骤开始的一切都必须重新执行。
ThinLTO
ThinLTO 是一种新的方法,旨在像非 LTO 构建那样进行扩展,同时保留了全 LTO 的大部分性能成就。 在 ThinLTO 中,串行步骤是非常薄和快速的。这是因为它不是加载比特码和合并一个单一的单体模块来进行这些分析,而是利用每个模块的紧凑摘要来进行串行链接步骤中的全局分析,以及为后来的跨模块导入的函数位置索引。当模块在完全并行的后端进行优化时,函数导入和其他 IPO 转换将在以后进行。
由 ThinLTO 全局分析实现的关键转换是函数导入,其中只有那些可能被内联的函数被导入到每个模块。这最大限度地减少了每个 ThinLTO 后端的内存开销,同时最大化了最有影响的跨模块优化机会。因此,IPO 转换是在每个模块上用其导入的函数进行扩展。 ThinLTO 的过程分为 3 个阶段。
- 编译:与完全的 LTO 模式一样生成 IR,但用模块摘要进行扩展。
- thin link:thin 链接器插件层,结合摘要并进行全局分析
- ThinLTO 后端:具有基于摘要的导入和优化的并行后端
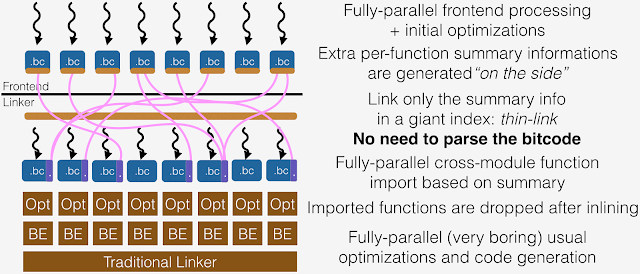
这个过程的关键因素是在第一阶段发出的摘要。这些摘要是使用比特码格式发布的,但设计成可以单独加载,而不涉及 LLVMContext 或任何其他昂贵的结构。每个全局变量和函数在模块摘要中都有一个条目。一个条目包含元数据,对它所描述的符号进行抽象。例如,一个函数被抽象为它的链接类型,它所包含的指令数量,以及可选的剖析信息(PGO)。此外,对另一个全局的每一个引用(采取的地址,直接调用)都被记录下来。这些信息可以在 Thin link 阶段建立一个完整的引用图,并利用全局总结信息进行后续快速分析。
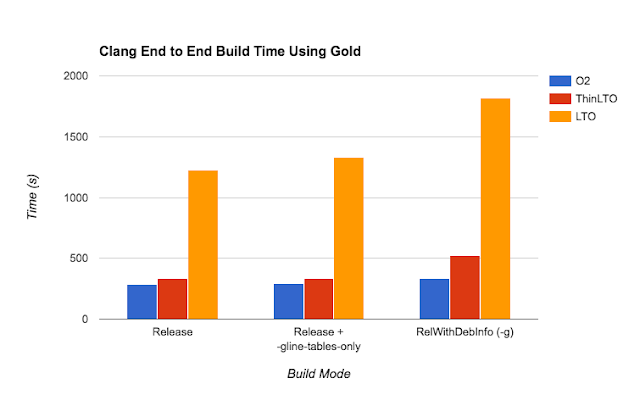
下面图片是 LTO 和 ThinLTO 的编译对比图;
IPO
过程间分析(inter-procedural analysis)是一个多步骤的过程,是 LTO 分析过程中的重要部分,也是一个跨模块的分析过程。跨模块的优化功能实现最早在 1987 年(Link time optimization - MIPS),后来相继出现了过程间分析和转换,动态链接程序的优化(IPA + LTO)。
GCC 中的 IPA 包含的操作有:increase alignment、devirtualization、constant propagation、inline、pure/const analysis 等。
ICC 中的 IPO(Interprocedural Optimization)包含众多的优化,例如:Array dimension padding、Alias analysis、Constant propagation、Dead call deletion、Dead function elimination、Inlining、Structure splitting and field reordering、Whole program analysis 等重要优化过程。优化选项配置为-ipo。
比如 inline 内联优化。
inline 内联优化
内联(inline)优化就是把调用的函数放到调用的地方,避免函数调用和寄存器的分配,增加指令的数量。
inline int Add(int a, int b)
{
return a + b;
}
int main()
{
int num1 = 1;
int num2 = 2;
int myNum = Add(num1, num2);
}
// 内联优化后
int main()
{
int num1 = 1;
int num2 = 2;
int myNum = num1 + num2;
}
优化后,取消函数调用的好处
1.它消除了函数调用过程中所需的各种指令:包括在堆栈或寄存器中放置参数,调用函数指令,返回函数过程,获取返回值,从堆栈中删除参数并恢复寄存器等。
2.由于不需要寄存器来传递参数,因此减少了寄存器溢出的概率。当使用引用调用(或通过地址调用或通过共享调用)时,它消除了必须传递引用然后取消引用它们。
除了有点,也有缺点:优化后的执行程序包变大。还有一些特定情况,内联将会造成很严重的后果,如递归函数的内联可能造成代码的无限 inline 循环。所以编译器在这些特殊情况下会拒绝内联,常见的包括虚调用,函数体积过大,有递归,可变数目参数,通过函数指针调用,调用者异常类型不同,declspec 宏、使用 alloca、使用 setjump 等。
可以通过关键字:inline 来实现内联优化。
其实内联 inline 只是建议性的关键字,编译器并不一定会听你的,毕竟他比你更了解你的代码编译后是什么样子的,而所谓的内联也不单单是指 inline 这个关键字了,他本质上是一种编译器的优化方式。另外,在 windows 上平台我还经常能看到【forceinline】(GCC 上的【always_inline】)这样的关键字,字面意思是强制内联。不过经过查阅,发现一般只是对代码体积不做限制了,或者说在 Debug 模式(不不开启优化的情况)下也会尽量按照开发者的意愿去内联。无论如何,最终的决定权还是交给编译器去处理。
死代码码消除 (Deadcode Elimination)
故名思义,就是一段代码没用上就会被删去。
int test() {
int a = 233;
int b = a * 2;
int c = 234;
return c;
}
上面的代码中,a 和 b 实际在后面的代码中没有用到,所以编译的时候可以直接优化掉,将被转换为
int test() { return 234; }
学习东西要有耐心,不要着急,不要焦虑,否则会影响自己的信心。要循序渐进,关键是保持持续的学习动力。编译器优化的内容很多,不必一次掌握。要逐个理解每个概念和原理。
更多阅读
- GRIN Compiler
- 编译优化之 - 过程间优化 (IPA/IPO) 入门
- 被知乎大佬嘲讽后的一个月,我重新研究了一下内联函数
- thinlto-scalable-and-incremental-lto
微信公众号:cdtfug,欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。