朋友,您好 ~

图片来自 Deepai 生成
看到一篇文章,囤积信息的坏习惯,作者像大多数程序员一样,浏览 hacknews、reddit 或 twitter(国内的浏览知乎、csdn、博客园),文章以技术为重点,主要还囤积信息,看到有些留言说,在浏览器打开接近 1000 个 tabs。
事实上,我不确定大多数人都会这样做,我只是希望我不是唯一的一个,我曾经就是这样。
这个应该就是 FOMO(fear of missing out 害怕错过)的心理,我相信大部分都是这样的。这不是病,是一种对知识和信息的获取渴望。
这些随机的知识,有什么用喃?
- windows 的出现:比尔盖茨有次意外的发现播种机的操作系统很难用,就想到开发一个易用的系统,可能对 windows 的出现有一定影响;
- macOS 的设计:乔布斯有一次意外的上了一次书法课,就造就一个很优雅的系统; ……
在工作中,我经常把一些意外的小东西,从大脑后面拉出来,并把它们归档,”以备不时之需”,这让我们感到震惊。有时,这个 “万一 “也会出现。
我注意到,现在的IT行业越来越不需要具备某种原始天赋,而更多的是需要了解由其他有天赋的人编写的工具、SDK 和 API。
在过去,你必须是魔法师,现在你只需要知道魔法师。
这些零碎,看起来是很意外的知识,不知道哪一天会影响到你自己的生活。
我被所有的科技信息所吸引,我喜欢发现新的和闪亮的东西,可以拓展自己的思路。
我喜欢看人们正在研究的东西,但信息量太大,我对此有一个小问题。虽然阅读一批较小的 30-40 个链接是可以应付的,但当数量在一个星期内增长到 80 多个时,就很费时,而且令人难以承受。
有人留言说,《百万富翁快车道》对这本书其中有一点是好的,那就是要专注于成为生产者而不是消费者的建议。。
毕竟,学习和信息汇总背后的想法是,你学习所有这些东西是为了更好地准备采取更正确、更快的行动。
同时,我觉得更重要的是要输出内容和自己的想法,从他们的链接里面获取和提炼他们的想法,而不是信息本身。
如果您喜欢这份 Newsletter,请转发给您朋友,,这是对我最大的帮助,继续进步,继续给大家带来有价值的分享。
文章推荐
本 PEP 提出了对 CPython 构建过程的修改,允许你构建一个无 GIL 的解释器。这种解释器将不与基于 GIL 的解释器 ABI 兼容,程序员将对 C 语言扩展中的一些锁定情况负责。如果实现的话,这将导致在后向兼容性问题不重要的情况下,能够在没有 GIL 的情况下运行。
作者讨论了如何优化 CUDA 矩阵乘法内核的性能。目标是将 NVIDIA 官方矩阵库 cuBLAS 的性能提高到 80% 以内;深入探讨凝聚全局内存访问、共享内存缓存、占用率优化等问题
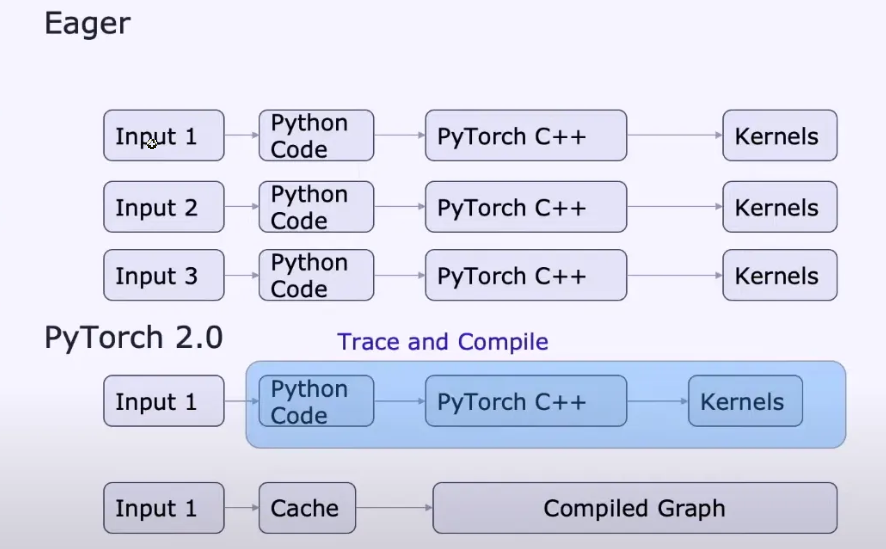
在过去的十年里,机器学习软件开发的格局发生了重大变化。许多框架来来去去,但大多数都严重依赖于利用 NVIDIA 的 CUDA,并且在 NVIDIA 图形处理器上表现最好。然而,随着 PyTorch 2.0 和 OpenAI 的 Triton 的到来,英伟达在这一领域的主导地位,主要是由于其软件护城河,正在被颠覆。
重复使用以前的系统中的组件,因为它的组件集成度很高,而且实施细节会从一个组件渗透到另一个。此外,这样的设计限制了系统的发展能力,因为更新一个组件会影响到很多组件,如果不重写系统,或者让系统瘫痪数小时,就很难甚至不可能做到这一点。
工具、资源推荐
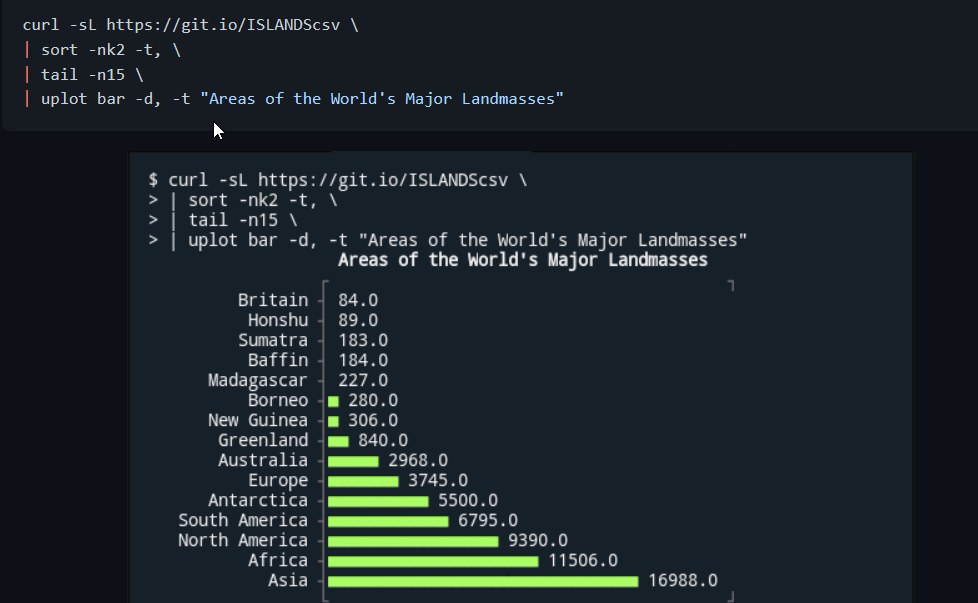
一个在终端上画图的命令行工具。
graphic-walker 允许数据科学家通过简单的拖放操作来分析数据并将模式可视化。