浅谈 LLVM LibFuzzer 介绍和实践
目录
- 什么是 Fuzzing Testing
- LLVm libFuzzer
- 环境准备
- 编译LLVM内建Fuzzer
- 提高 Fuzzer 效率
- Hello World Fuzzer
- 总结
导读:通过本文我们可以知道什么是 Fuzzer、LibFuzzer,如何编译LLVM-Fuzzer,以及快速写一个 Hello world Fuzzer 目标函数。
什么Fuzzing Test
在编程和软件开发中,或多或少听过Fuzzing 测试,是一种自动化的软件测试技术,其核心思想是将自动或半自动生成的随机数据输入到一个程序中,并监视程序异常,如Crash,Assertion失败,以尽可能的发现程序错误,比如内存泄漏。Fuzzing 测试常常用于检测软件或计算机系统的安全漏洞。
通常,Fuzzer 用于测试采用结构化输入的程序。这个结构是特定的,例如,在一个文件格式或协议,并区分有效的和无效的输入。在用代码不同分支,会有意想不到的行为,无效输入就导致得不到正确处理。
Fuzzer 可以从几个方面进行分类,生成型、突变型、以及结合这 2 种情况的。今天介绍的是最后一种,就是 LLVM 自带 LibFuzzer。
什么是 LibFuzzer
顺带提一下这个当今强大的编译器框架 LLVM 是什么?
LLVM 是一套编译器和工具链技术,可用于
开发任何编程语言的前端和任何指令集架构的后端。LLVM 是围绕独立于语言的中间表示(IR)设计的,它作为一种可移植的高级汇编语言,可以通过多次转换进行优化。
LibFuzzer 与被测库链接,并通过特定的 Fuzzy 入口点,又称目标函数,将 Fuzzy 输入提供给库;然后,Fuzzer 跟踪到达的代码区域,并在输入数据的主体上生成不同的参数组合,以最大限度地提高代码覆盖率。libFuzzer 的代码覆盖率信息由 LLVM 的 SanitizerCoverage 工具提供。
libFuzzer 有 3 个特性:第一个是 in-process 指进程内,即 libFuzzer 在 fuzz 时并不是产生出多个进程来分别处理不同的输入,而是将所有的测试数据放入进程的内存空间中。
这个对数据传输就相当的高效,为了提高这种高输入,甚至还可以结合了 Google 序列化结构化数据库 protobuf,比如目前 LLVM 里面的 clang-proto-fuzzer 就是这种类型。
第二个特性是 coverage-guided 指覆盖率。Fuzzer是随机的测试,不知道测试了多少代码覆盖,那就可以用这个特性来统计代码覆盖率。
第三个特性就是Evolutionary, libFuzzer 不仅可以生成数据,还可以对目前的数据进行突变,如前面讲到的,结合了生成和突变两种形式。
不过这些特性也一定上约束了libFuzzer 的某些场景的使用,比如在内存上完成生成、突变作为输入,速度非常的快,这样需要避免目标函数太大,太复杂。以及其他的限制,不能有exit()函数。
对于 fuzzer 的时候,在编译目标函数的时候,需要指定-fsanitize类型,有AddressSanitizer (ASAN), UndefinedBehaviorSanitizer (UBSAN), 以及 MemorySanitizer (MSAN)。
环境准备
这么强大的工具,为了给我们更多的程序员用,libFuzzer是独立的,也就是不依赖于 LLVM 框架,用的时候只需要下载对应的库和头文件即可,在 ubuntu 和 centos 以及windows,都可以快速的获取到,关键字搜索:llvm-toolset。
下面举例在 LLVM 上,使用原生的编译 Libfuzzer 和针对 LLVM 测试。
首先是Clone LLVM 的 repo,然后编译 LLVM 和compile-rt,命令如下。
git clone [email protected]:llvm/llvm-project.git && cd llvm-project
mkdir build && cd build
cmake -GNinja -DCMAKE_BUILD_TYPE=Release ../llvm \
-DLLVM_ENABLE_PROJECTS="clang;lld;compiler-rt;clang-tools-extra" \
-DLLVM_DYLIB_COMPONENTS=all \
-DLLVM_TARGETS_TO_BUILD="MetaXGPU;AMDGPU;X86"
这里推荐编译类型为 Release,因为 debug 的编译实在是太慢了,拿我来自己的情况来说,前者 10 分钟内可以完成,后者大概 2 个小时。
如果是要用 LLVM 自带的LLVM-fuzzer tool,可以编译里面自带的 Fuzzer 工具,可以参考下面的命令,编译好之后,会带有clang-fuzzer、llvm-as-fuzzer、llvm-isel-fuzzer、llvm-mc-fuzzer等,可以用于测试 LLVM 自己前后端的功能,汇编、反汇编、指令选择、优化等等。
mkdir build_fuzzer & cd build_fuzzer
cmake -GNinja -DCMAKE_BUILD_TYPE=Release ../llvm \
-DLLVM_ENABLE_PROJECTS="clang" \
-DLLVM_USE_SANITIZER=Address \
-DLLVM_USE_SANITIZER_COVERAGE=On \
-DMAKE_C_COMPILER=$LLVM_PEOJECT/build/bin/clang
指的注意的是需要指定-DMAKE_C_COMPILER为上一步编译 LLVM 的 clang 文件,而且是不同的 build 目录。
就地取材,用 compiler-rt/test/fuzzer/CompressedTest.cpp 来编译完成之后,来跑一个,
% clang -O -g CompressedTest.cpp -fsanitize=fuzzer -lz
% ./a.out
INFO: Seed: 127598651
...
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 2 ft: 3 corp: 1/1b lim: 4 exec/s: 0 rss: 25Mb
#2097152 pulse cov: 2 ft: 3 corp: 1/1b lim: 4096 exec/s: 1048576 rss: 25Mb
#4194304 pulse cov: 2 ft: 3 corp: 1/1b lim: 4096 exec/s: 1048576 rss: 25Mb
#8388608 pulse cov: 2 ft: 3 corp: 1/1b lim: 4096 exec/s: 1198372 rss: 26Mb
#16777216 pulse cov: 2 ft: 3 corp: 1/1b lim: 4096 exec/s: 1290555 rss: 26Mb
#33554432 pulse cov: 2 ft: 3 corp: 1/1b lim: 4096 exec/s: 1342177 rss: 26Mb
#67108864 pulse cov: 2 ft: 3 corp: 1/1b lim: 4096 exec/s: 1398101 rss: 26Mb
...
artifact_prefix='./'; Test unit written to ./crash-40bb78ac4...: TUVUQQ==
上面运行之后的日志信息里面,可以看到这些信息,分别代表的意思如下:
- Seed 这个 seed 就是./a.out -seed=xxx可以指定的随机seed
- INFO 第一行提示没有指定corpus,corpus是一个提高 fuzzer 效率的方法
- #2 后面的 INITED 代表初始化,开始执行,其他还有 pulse 是代表在运行,只是没有新的产生,执行了 2 的 n 次方个后会显示这个 pulse,有新的输入产生会显示 new 等等
- cov: 2 代表覆盖率是2, 执行当前输入所覆盖的代码块的总数
- ft: 3 feature泛指代码覆盖率: 边缘覆盖率、边缘计数、配置文件等
- corp: 1/1b 当前内存中测试输入 corpus 库中的条目数及其大小(以字节为单位)。
- lim: 4 exec/s 当前对语料库中新条目长度的限制。随时间增加,直到达到设置的最大长度(-max_len),目前长度是4
- rss: 25Mb 当前内存消耗,当前是25Mb
- ./crash-xxx 这个就是用来复现问题的 binary 文件,方便吧
最后的一个 crash 文件是用于复现问题,这样我们就可以有针对性的对程序进行动态调试,利用造成 crash 的输入重现出漏洞的细节。
提高 Fuzz 效率
可以看到一个简单的 Fuzzer 目标函数,执行之后的一些打印信息。同时在执行的时候 libFuzzer 还内置了一些可选参数可以供我们使用,比如在最大长度默认是100,如果某个 bug 输入的参数长度是 101 才能触发,那这个 bug 用长度 100 的输入的几乎永远都跑不出来。
因此可见,我们可以设置一些常见的可选参数也可以提高效率,并且找到真正的问题所在。有如下这些参数是比较常见的。
- -max_len 生成输入的最大长度
- -len_control 首先尝试生成较小的输入,越小就代表执行的速度就越快,然后随着时间的推移尝试生成较大的输入
除了这些常见的可选参数之外,还有 2 个对于提高效率也是非常重要的:dict和corpus。
Dict 字典
相信「字典」对我们来说,并不陌生,基本上小学的时候,人手一本「新华字典」,不过因为我当时家里贫寒,和我姐共用了一本字典,我就说难怪我现在普通话不好。
字典是从一种或多种特定语言的词典中列出的词汇,通常按字母顺序排列。

对于 Fuzzer 的字典,就是从一个目标函数中列举出他的所有输入特性相关的词汇。比如对应编译器的MC(machine code),字典就包括不限于:指令集、寄存器、const常量、寄存器宽度等等。
再举个我们程序员熟悉的例子,常见的编程语言,包含有条件、跳转、逻辑处理等等,对应的字典包括不限于:if、else、for、defined、template、include、pragma、!=、+=等等,这个相对比较好理解了。
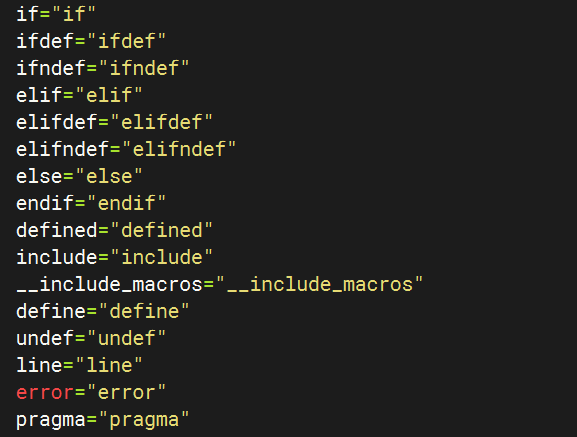
Fuzzer 字典的好处提供一组我们希望在输入中找到的常用词或值来作为输入帮助 Fuzzer 更快扩大其覆盖范围。使用也非常的简单,用-dict参数即可:./a.out -dict=dict.txt。
字典除了自己生成一个,还有就是每次跑完之后 libFuzzer 会提供一个建议的字典,然后主需要更新到对应的 dict 文件里面即可。
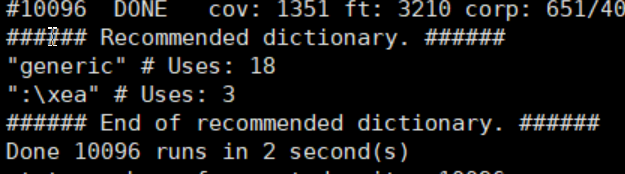
Corpus 语料库
Corpus 语料库,可以想象为一个函数的参数,各种参数的组合,即 Fuzzer 的测试用例。
在未使用语料库的情况下就得到了crash,实属意外收获。如果我们在使用字典的下情况仍然暂时未得到crash,另一个方法可以去寻找一些有效的输入语料库。因为 libFuzzer 是进化型的fuzz,结合了产生和突变两个发面。
如果我们可以提供一些好的语料库,虽然它本身没法造成程序 crash,但 libFuzzer 会在此基础上进行变异,就有可能变异出更好的输入参数,从而增大程序 crash 的概率。具体的变异策略需要我们去阅读 libFuzzer 的源码或者些相关的文章,不懂就网上搜,毕竟我们程序员最大的优势就是动手,关键还免费。
在许多情况下,提供语料库可以将代码覆盖率提高一个数量级。
在学习 Fuzzer 时候找到的一些资料,可以参考 Google Oss-Fuzz 开源仓库,语料库不是所有的场景都适合。特别适用于严格定义的文件格式和数据传输协议,比如:
- 对于文件格式解析器,添加测试套件中的有效文件
- 对于协议解析器,将测试套件中的有效原始流添加到单独的文件中
- 对于图形库,添加各种小的PNG/JPG/GIF文件
执行的时候,只需要在目标函数后面跟一个目录即可,./a.out corpus,这里的 corpus 目录就是用来存放 corpus 集的。随着运行时间而增长变多。
同时可以精简合并corpus,./a.out -merge=1 corpus_min corpus, 这样,corpus_min和 corpus 将会存放到新的 corpus 精简后的输入样例。
提高效率,可以从可选参数的组合、字典、以及 corpus 这 3 方面入手,基本上可以保证我们目标函数的稳定性了,除了这些手段外,还有一个重要的也是难点,就是怎么写好一个目标函数。
Show Me The Code
下面就从几个简单的 Hello world 入手,熟悉下 libFuzzer 如何写一个目标函数。
创建一个文fuzz_target.cc, 这个内容如下,记得不要使用使用 main 等作为函数名,因为 Libfuzzer 自带了 main 函数。
#include <stdint.h>
#include <stddef.h>
// function under test
bool foo(const uint8_t *data, size_t size){
return size >= 4
&& data[0] == 'M'
&& data[1] == 'E'
&& data[2] == 'T'
&& data[3] == 'A'
&& data[4] == 'X';
}
// fuzzing target called by fuzzing engine
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size){
foo(data, size);
return 0;
}
需要注意的是 LLVMFuzzerTestOneInput 函数是我们要实现的接口函数,他的两个参数 Data (libFuzzer的测试样本数据),size (样本数据的大小)。
分析问题:当 foo 函数被调用的时候,条件 size>=4,但是data[4], index 取到 4,相当于 size 应该是 5,就会触发超出边界的异常。
编译这个文件,命令clang++ -g -O1 -fsanitize=fuzzer,address fuzz_target.cc -o fuzzer_target ,这里的 clang 是用 llvm 编译出来的。
如果是直接安装的 clang,就需要添加 libFuzzer的库函数:clang++ -g -O1 -fsanitize=fuzzer,address libFuzzer/Fuzzer/libFuzzer.a fuzz_target.cc -o fuzzer_target,否则可能会报错。
参数的意思:
- -g 可选参数,保留调试符号
- -O1 指定优化等级为 1,对应的还有 O0 (optimize 0,1,2),以及 OS(optimize size)使用后 binary 大小会变小
- -fsanitize 指定 sanitize, 类型有几种:fuzzer,address,和memory(单独使用,检查内存),undefined(未定义)
编译这一步骤整体过程就是通过 clang 的 -fsanitize=fuzzer 选项可以启用 libFuzzer,这个选项在编译和链接过程中生效,实现了条件判断语句和分支执行的记录,通过生成不同的测试样例然后能够获得代码的覆盖率情况,最终实现所谓的 fuzz-testing。
注意:编译的选项会影响 fuzzer 的效率,比如下面就是一个点。我也不知道有哪些,遇到问题就在网上搜,一定会有结果的,不行就问下身边的大佬,还有就是顺便关注下我们「沐曦MetaX」,会有意想不到的收获。
-
clang 编译的时候,参数
-fno-omit-frame-pointer对于不需要栈指针的函数就不在寄存器中保存指针,因此可以忽略存储和检索地址的代码,同时对许多函数提供一个额外的寄存器。在 AMD64 平台上此选项默认打开,但是在 x86 平台上则默认关闭,建议显式的设置它。 -
gline-tables-only 表示使用采样分析器, 在应用程序执行时,抽样探查器用于收集运行时信息(如硬件计数器)。一般情况下,这个参数非常有效,并且不会引起大量的运行时开销。
分析器收集的示例数据可用于编译期间,以确定代码中执行最多的区域是什么,在编译器可以使用分析信息之前,代码需要在分析器下执行,这也对提高我们 Fuzzing 效率很重要。
那大体常用的编译命令就是这样:clang++ -g -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link test.cc libFuzzer/Fuzzer/libFuzzer.a -o test
我们的第一个目标函数里面被调用的 foo 函数是硬编码,有没有一种好的方法直接生成输入数据呢?YES,上代码。
#include <stdint.h>
#include <stddef.h>
#include <fuzzer/FuzzedDataProvider.h>
// function under test
uint64_t foo_1(uint64_t value, uint64_t amount){
if(amount > 64) return 0;
return value << amount;
}
// fuzzing target called by fuzzer
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size){
if(size < sizeof(uint64_t)*2) return 0;
//1. extract from array
uint64_t value = ((uint64_t*)data)[0]; // extract first
uint64_t amount = ((uint64_t*)data)[1]; // extract second
return foo_1(value, amount);
//2. use dataprovider
FuzzedDataProvider fuzdata(data, size);
uint64_t value = fuzdata.ConsumeIntegral<uint64_t>();
uint64_t amount = fuzdata.ConsumeIntegral<uint64_t>();
return foo_1(value, amount);
}
用 FuzzedDataProvider 这样一个 helper,组合生成我们需要的数据,上面 2 段代码分别获取value, amount,可以达到相同的效果。
不怕你们知道,我也是一个才接触 libFuzzer 不久,在后来的编写 Fuzzer 过程中,还发现一些小技巧,比如可以用 LLVMFuzzerCustomMutator 来对现有的数据进行突变,然后输入到目标函数。除了突变还可以用 LLVMFuzzerCustomCrossOver 来自定义数据的交叉组合。从而在相同时间内达到更高的代码覆盖率。
总结
通过本文我们可以知道 Fuzzer、LibFuzzer,以及如何编译 LLVM-Fuzzer,以及写一个 Fuzzer 目标函数,由于篇幅太长,不利于吸收,效果比较差。还有如何管理 corpus、crash bug、集成到我们项目中,都是要去掌握和了解,这就留给我们后面去完成吧。就我了解的而言,libFuzzer是 Fuzzing 工具中最常见之一,它还是独立的,不依赖LLVM,提供的接口和 helper 是非常强大的,
在运行的过程中,还需要用 dict、corpus 来提高 Fuzzing 的效率。corpus 语料库在 Fuzzy 过程中不断演变,我们可以找到经过代码中以前未知路径的输入。随着运行时间的增加,要不断的优化 merge 我们的corpus,用较小的输入达到同样的覆盖率。
最后,利用 libFuzzer 可以发现包括不限于这些 crash:堆/堆栈/全局越界(OOM)、释放后使用、返回后使用、未初始化内存读取、内存泄漏或未初始化、互斥作用等。
最最后,Fuzzer 有很多类型的,开源、半开源、商业等,比如面向安全 Google-honggfuzz、面向 HTTP 的 Fuzz-Monkey。选择适合项目的就好,适合自己的就行。所以说 libFuzzer 只是一个工具,但是要解决问题的还是我们自己。