Fuzzing 是一种软件测试方法,将格式不正确的数据作为输入传递给程序,并查看其是否存在不正确的行为。今天 fuzzing 是发现软件安全问题的最有效的方法之一。2014年第一个覆盖引导模糊器Fuzzy Lop。这开创了现代市场上的模糊解决方案和技术。
什么是LibFuzzer
LibFuzzer is in-process, coverage-guided, evolutionary fuzzing engine.
LibFuzzer与被测库链接,并通过特定的模糊化入口点(又称“目标函数 target function”)将模糊化输入提供给库;然后,模糊器跟踪到达的代码区域,并在输入数据的主体上生成不同的参数组合,以最大限度地提高代码覆盖率。libFuzzer的代码覆盖率信息由LLVM的SanitizerCoverage工具提供。
提供:
简单来说就是通过与要进行fuzz的库连接,并将libfuzzer生成的输入通过模糊测试进入点(fuzz target)喂给要fuzz的库进行fuzz testing。同时fuzzer会跟踪哪些区域的代码已经被测试过的,并且根据种料库的输入进行变异来使得代码覆盖率最大化。代码覆盖率的信息是由LLVM’s SanitizerCoverage插桩提供的
需要注意的是这几个libfuzzer的特性:in-process指进程内。即libfuzzer在fuzz时并不是产生出多个进程来分别处理不同的输入,而是将所有的测试数据放入进程的内存空间中。coverage-guided指覆盖率指导的。即会进行代码覆盖率的计算,正如定义所说的使得不断增大代码覆盖率。evolutionary是指libfuzzer是进化型的fuzz,结合了产生和变异两种形式。
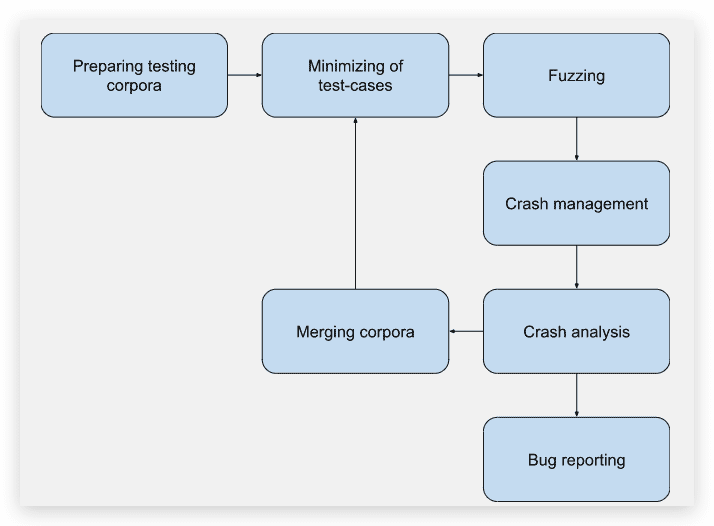
举例 fuzzing-test
创建一个文件,fuzz_target.cc, 这个内容如下,记得不要使用使用main等作为函数名。
// fuzz_target.cc
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *Data, size_t Size) {
DoSomethingInterestingWithMyAPI(Data, Size);
return 0; // Non-zero return values are reserved for future use.
}
需要注意的是 LLVMFuzzerTestOneInput 函数是我们要实现的接口函数,他的两个参数Data(libfuzzer的测试样本数据),size(样本数据的大小)。
DoSomethingInterestingWithMyAPI 函数即我们实际要进行fuzz的函数。
编译这个文件,命令clang++ -g -O1 -fsanitize=fuzzer,address fuzz_target.cc -o fuzzer_target ,这里的clang是我们用llvm编译出来的,如果用的其他方式会报错。
参数的意思:
- -g 可选参数,保留调试符号。
- -O1 指定优化等级为1,对应的还有O0 (optimize 0,1,2),以及OS(optimize size)使用后binary大小会变小。
- -fsanitize 指定sanitize, 值有几种:fuzzer,address,memory(单独使用,检查内存),undefined(移除、未定义等)
这一步骤整体过程就是通过clang的-fsanitize=fuzzer选项可以启用libFuzzer,这个选项在编译和链接过程中生效,实现了条件判断语句和分支执行的记录,通过生成不同的测试样例然后能够获得代码的覆盖率情况,最终实现所谓的fuzz-testing。
注意:编译的选项会影响fuzzer的效率,比如下面就是一个点。我也不知道有哪些,遇到问题就在网上搜吧,一定会有结果的。
- clang编译的时候,参数
-fno-omit-frame-pointer对于不需要栈指针的函数就不在寄存器中保存指针,因此可以忽略存储和检索地址的代码,同时对许多函数提供一个额外的寄存器。所有”-O”级别都打开它,但仅在调试器可以不依靠栈指针运行时才有效。在AMD64平台上此选项默认打开,但是在x86平台上则默认关闭。建议显式的设置它。 - gline-tables-only:表示使用采样分析器, 在应用程序执行时,抽样探查器用于收集运行时信息(如硬件计数器)。它们通常非常有效,并且不会引起大量的运行时开销。分析器收集的示例数据可用于编译期间,以确定代码中执行最多的区域是什么,在编译器可以使用分析信息之前,代码需要在分析器下执行。这也对提高我们fuzz效率很重要。
比如常用的编译命令:clang++ -g -O2 -fno-omit-frame-pointer -gline-tables-only -fsanitize=address,fuzzer-no-link test.cc -o test
写一个fuzz 测试函数
- 准备被测文件
比如有一个头文件, test.h, 里面有一个FuzzFunction1的函数
bool FuzzFunction1(const uint8_t* data, size_t size) {
bool result = false;
if (size >= 3) {
result = data[0] == 'F' &&
data[1] == 'U' &&
data[2] == 'Z' &&
data[3] == 'Z';
}
return result;
}
- 写测试函数
现在要对着头里面里面的FuzzFunction1函数进行测试,编一个测试接口,test.cc,
#include "test.h"
extern "C" int LLVMFuzzerTestOneInput(const uint8_t *data, size_t size) {
FuzzFunction1(data, size);
return 0;
}
需要注意的是,data和size和头文件里面的类型是一致的。如果是bool类型的,记得false和true,都要遍历bool bool_flag[] = {true, false}。
- 编译测试函数
只有就完成了,然后编译下面的测试接口函数clang++ -g -std=c++11 -fsanitize=fuzzer,address test.cc -o test.,生成一个test的执行文件
- 创建一个corpus(语料库,可以想象为一个函数的参数,各种参数的组合)
在未使用语料库的情况下就得到了crash实属意料之外,如果我们在使用字典的下情况仍然暂时未得到crash,另一个方法可以去寻找一些有效的输入语料库。因为libfuzzer是进化型的fuzz,结合了产生和变异两个发面。如果我们可以提供一些好的seed,虽然它本身没法造成程序crash,但libfuzzer会在此基础上进行变异,就有可能变异出更好的语料,从而增大程序crash的概率。具体的变异策略需要我们去阅读libfuzzer的源码或者些相关的论文。
mkdir corpus
./test corpus
corpus 是我们提供的语料库。理想情况下,该语料库应该为被测代码提供各种有效和无效的输入,模糊器基于当前语料库中的样本输入生成随机组合。
如果组合触发了测试代码中先前未覆盖的路径的执行,则该组合参数将保存到语料库中以供将来变更。
当然LibFuzzer也可以没有任何初始seed的情况下工作,但如果受测试的库接受复杂的结构化输入,则会因为随机产生的样例不易符合导致效率降低。
合并corpus,./test -merge=1 corpus_min corpus, 这样,corpus_min和corpus将会存放到新的corpus精简后的输入样例。
执行的时候,我们一般会看到如下信息
➜ 04 Rik:(master) ✗ ./test corpus
INFO: Seed: 2222548757
INFO: Loaded 1 modules (35 inline 8-bit counters): 35 [0x7f7120, 0x7f7143),
INFO: Loaded 1 PC tables (35 PCs): 35 [0x5b7a68,0x5b7c98),
INFO: 0 files found in corpus1
INFO: -max_len is not provided; libFuzzer will not generate inputs larger than 4096 bytes
INFO: A corpus is not provided, starting from an empty corpus
#2 INITED cov: 3 ft: 3 corp: 1/1b exec/s: 0 rss: 27Mb
#3 NEW cov: 4 ft: 4 corp: 2/4b lim: 4 exec/s: 0 rss: 27Mb L: 3/3 MS: 1 CMP- DE: "\x00\x00"-
#1190 NEW cov: 5 ft: 5 corp: 3/7b lim: 14 exec/s: 0 rss: 27Mb L: 3/3 MS: 2 ChangeBinInt-CMP- DE: "F\x00"-
……………………
artifact_prefix='./'; Test unit written to ./crash-0eb8e4ed029b774d80f2b66408203801cb982a60
- Seed 这个seed,就是./test -seed=xxx可以指定的随机seed
- max_len 测试输入的最大长度
- cov 代码覆盖率,我们的语料库达到的代码块总数
- corp 语料库中的文件数量及其总大小
- exec/s 每秒模糊迭代次数(在运行时间长于 < = 1秒的情况下有用)
- rss 存储在物理内存中的进程内存量
- ./crash-xxx 这个就是用来复现问题的文件,方便吧
- INITED fuzzer已完成初始化,其中包括通过被测代码运行每个初始输入样本。
- READ fuzzer已从语料库目录中读取了所有提供的输入样本。
- NEW fuzzer创建了一个测试输入,该输入涵盖了被测代码的新区域。此输入将保存到主要语料库目录。
- pulse fuzzer已生成 2的n次方个输入(定期生成以使用户确信fuzzer仍在工作)。
- REDUCE fuzzer发现了一个更好(更小)的输入,可以触发先前发现的特征(设置-reduce_inputs=0以禁用)
最后的一个crash文件, 这样我们就可以有针对性的对程序进行动态调试,利用造成crash的输入回溯出漏洞的细节。
如何理解fuzzer的输出结果
#17458 REDUCE cov: 7 ft: 7 corp: 5/14b lim: 170 exec/s: 0 rss: 29Mb L: 4/4 MS: 1 EraseBytes-
指尝试了17458个输入,成功发现了5个样本(放入语料库)大小为14b,共覆盖了7个代码块,占用内存29mb,变异操作为EraseBytes-

要使用libfuzzer的功能
就需要再llvm里面变异compiler-rt,然后可以使用clang++ -fsanitizer=Address xx.cc 在compiler-rt目录下有一些example cc的文件
编译llvm-mc-assemble-fuzzer
这个是汇编器的,还有其他的, 编译这个用之前的编译的llvm里面的clang,就需要替换为这个,用flag=cmake_c_compiler=xxx/clang 而且目录不能是同一个,不然cmake会失败。
fuzzer的dict
提高我们fuzz的效率,这其中一个办法就是使用字典。
我们知道基本上所有的程序都是处理的数据其格式是不同的,比如 xml文档, png图片等等。这些数据中会有一些特殊字符序列 (或者说关键字), 比如在xml文档中就有CDATA,<!ATTLIST等,png图片就有png 图片头。如果我们事先就把这些字符序列列举出来吗,fuzz直接使用这些关键字去组合,就会就可以减少很多没有意义的尝试,同时还有可能会走到更深的程序分支中去。
比如下面就是xml.dict里面的内容,xml一般有encoding、version、href等,用这些来组合,比其他的组合更高效,用例少,速度快,更精准。
attr_encoding=" encoding=\"1\""
attr_generic=" a=\"1\""
attr_href=" href=\"1\""
attr_standalone=" standalone=\"no\""
attr_version=" version=\"1\""
执行的时候指定dict,用参数-dict ./test -max_total_time=60 -print_final_stats=1 -dict=./xml.dict corpus,如果corpus太多,可以用merge来精简为一个。
文章太长了。主要是这个工具太强大了。
最后的进阶
下面是关于一些链接库的选择以及插桩编译时的一些参数的设置,还有max_len的设置对我们最后fuzz结果的影响。
编译的插桩参数
插桩的参数-fno-omit-frame-pointer -gline-tables-only,这2个前面提到过了,再来介绍一个fuzzer-no-link。
如果修改大型项目的CFLAGS,它也需要编译自己的主符号的可执行文件,则可能需要在不链接的情况下仅请求检测,即fuzzer-no-link强制在链接阶段不生效。
介绍一些新的参数,是关于ld的。
比如编译命令:
clang -O2 -fno-omit-frame-pointer -gline-tables-only \
-fsanitize=address,fuzzer-no-link -fsanitize-address-use-after-scope test.cc \
-Wl,--whole-archive xxx/.libs/libpcre2-8.a xx/.libs/libpcre2-posix.a \
-Wl,-no-whole-archive -fsanitize=fuzzer -o test
参数:–whole-archive和–no-whole-archive是ld专有的命令行参数,clang++并不认识,要通过clang++传递到ld,需要在他们前面加-Wl。–whole-archive可以把 在其后面出现的静态库包含的函数和变量输出到动态库,–no-whole-archive则关掉这个特性。
执行的max_len的参数
max_len一般情况下,越大获得的corpus就越多,就越容易挖掘出bug。
./test ./corpus1 -print_final_stats=1 -max_len=500 -max_total_time=100
解释,运行test,长度为500,并打印最后的结果,执行事假哪位100s,执行的corpus保存到corpus1里面。
编译llvm fuzz参考:https://github.com/google/oss-fuzz/blob/master/projects/llvm/build.sh
cmake -GNinja -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=On -DLLVM_ENABLE_WERROR=On -DLLVM_USE_SANITIZER=Address -DLLVM_USE_SANITIZE_COVERAGE=On -DCMAKE_C_COMPILER=/usr/local/bin/clang ../llvm
cmake -GNinja -DCMAKE_BUILD_TYPE=Release ../$LLVM \
-DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;compiler-rt;lld;clang-tools-extra" \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DCMAKE_C_COMPILER="${CC}" \
-DCMAKE_CXX_COMPILER="${CXX}" \
-DCMAKE_C_FLAGS="${CFLAGS}" \
-DCMAKE_CXX_FLAGS="${CXXFLAGS}" \
"${CMAKE_FUZZING_CONFIG}" \
-DLLVM_NO_DEAD_STRIP=ON \
-DLLVM_USE_SANITIZER="${LLVM_SANITIZER}" \
-DLLVM_EXPERIMENTAL_TARGETS_TO_BUILD=WebAssembly \
-DCOMPILER_RT_INCLUDE_TESTS=OFF
Read more
https://llvm.org/docs/LibFuzzer.html
https://blog.haboob.sa/blog/applying-fuzzing-techniques-against-pdftron-part-2
https://www.moritz.systems/blog/an-introduction-to-llvm-libfuzzer/
https://github.com/Dor1s/libfuzzer-workshop
https://www.anquanke.com/post/id/224823
微信公众号:cdtfug, 欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。