可以用 CUDA 创建大规模并行处理机应用程序的方法之一。它允许您使用强大的 c++ 编程语言来开发高性能算法,这些算法由运行在 GPU 上的数千个并行线程加速。
许多开发人员已经通过这种方式加速了他们计算和带宽需求量巨大的应用程序,包括支持深度学习这一人工智能革命的库和框架。
需要有NV显卡的电脑,环境准备,我用的thinkpad,装的windows,在wsl下面安装cuda,参考官方的文档:
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-11-7-local_11.7.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-11-7-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda
下面用c代码和cuda来比较下.
C 代码
void c_hello(){
printf("Hello World!\n");
}
int main() {
c_hello();
return 0;
}
CUDA 代码
__global__ void cuda_hello(){
printf("Hello World from GPU!\n");
}
int main() {
cuda_hello<<<1,1>>>();
return 0;
}
主要上面的 cuda代码里面,有一个<<<>>>和__global__,global指的是在GPU device侧运行, global 函数就是kernel.
device和host的区别:分别是GPU,一个是CPU.
要在 GPU 上计算,需要分配 GPU 可访问的内存。CUDA 中的统一内存通过提供一个单一的内存空间容易访问所有的 gpu 和 cpu 。要在统一内存中分配数据,请调用 cudaMallocManaged() ,它返回一个指针,可以通过主机(CPU)代码或设备(GPU)代码访问该指针。
要释放数据,只需传递指针到 cudaFree()。
再回到上面的代码中,cuda_hello<<<1,1>>>(); ,这里的«<»>这个是特殊语法,cuda_hello是kernel函数,里面有1,1,第一个1的含义是:block的数量, 一群这样的block称为grid(网格),并行的线程集合称为block.
上面的第一个和第二个分别可以,像下面这么定义:
int blockSize = 256;
int numBlocks = (N + blockSize - 1) / blockSize;
cuda_hello<<<numBlocks, blockSize>>>();
CUDA gpu 有许多并行处理器组成流多处理器,或者SM(shared memeory)。每个 SM 可以运行多个并发线程块。例如,一个基于 Pascal GPU 架构的 Tesla P100 GPU 有56 SM,每SM最多可支持2048个活动线程。为了充分利用所有这些线程,我应该启动带有多个线程块的内核。
第二个1的意思是多少个线程,这个数是32的倍数,在cuda里面,可以用blockDim.x获取线程的数量,threadIdx.x这个获取当前线程的index.
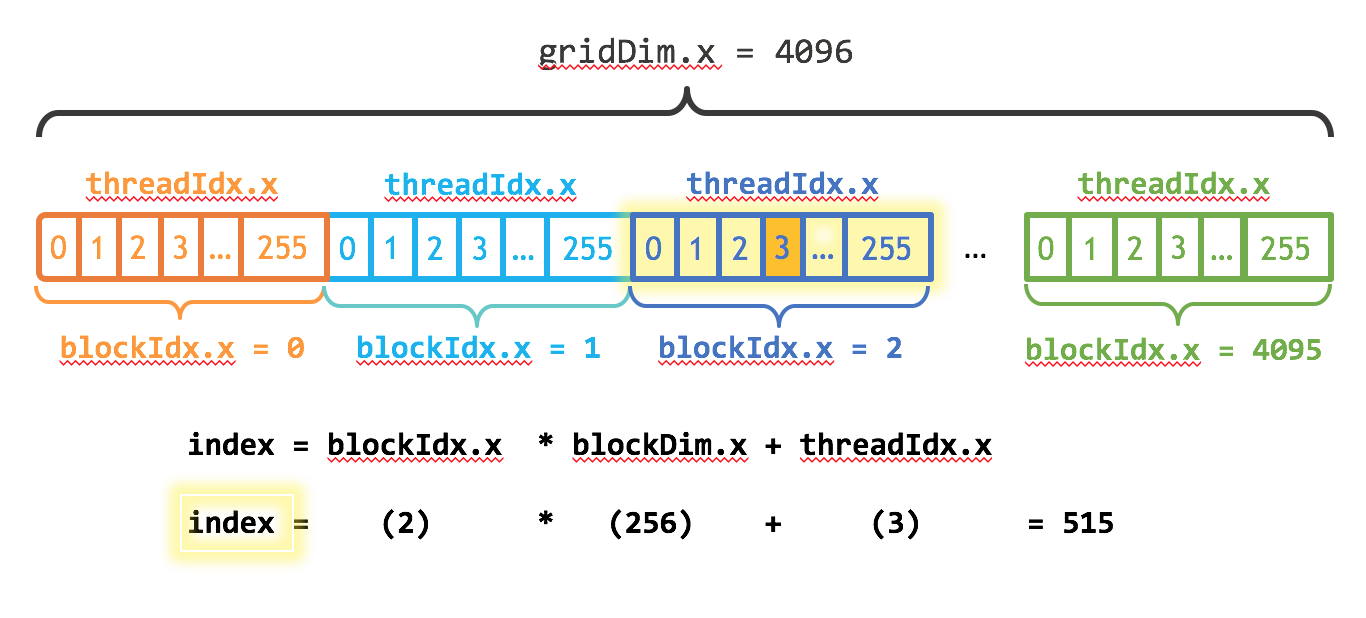
cuda 还提供了用blockIdx.x, gridDim.x,分别获取block的index和块的数量.
所以就可以通过上面内置的函数获取偏移量
__global__
void add(int n, float *x, float *y)
{
int index = blockIdx.x * blockDim.x + threadIdx.x;
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
y[i] = x[i] + y[i];
}
比如下面就是求第三个黄色区域值的index.
- 分配主机内存和初始化的主机数据
- 分配设备内存
- 将输入数据从主机传输到设备存储器
- 执行内核
- 将输出从设备存储器传输到主机
如果没有NVIDIA的显卡,下一个介绍下如何使用google colab提供的免费GPU来测试下。
Read more
https://www.nvidia.com/docs/IO/116711/sc11-cuda-c-basics.pdf
https://cuda-tutorial.readthedocs.io/en/latest/tutorials/tutorial01/
https://developer.nvidia.com/blog/even-easier-introduction-cuda/
微信公众号:cdtfug, 欢迎关注一起吹牛逼,也可以加微信号「xiaorik」朋友圈围观。