翻译的一篇文章, 重要是从Linux日志中日趋攻击自己统计。
https://dev.to/pluralsight/analyzing-the-attacks-on-my-website-30jf
最近,我在我的博客上做了一次安全审计,决定深入研究一下我的安全日志 jeremymorgan.com。 通过一些 Linux 命令行功夫,一些 Golang,和谷歌表格,我能够得到一个非常好的想法,攻击来自哪里。
首先,我使用 CentOS 托管我的站点,所以我检查了 /var/log/secure。 此日志是身份验证日志存储在我的服务器上的位置。
这是日志文件的样子:
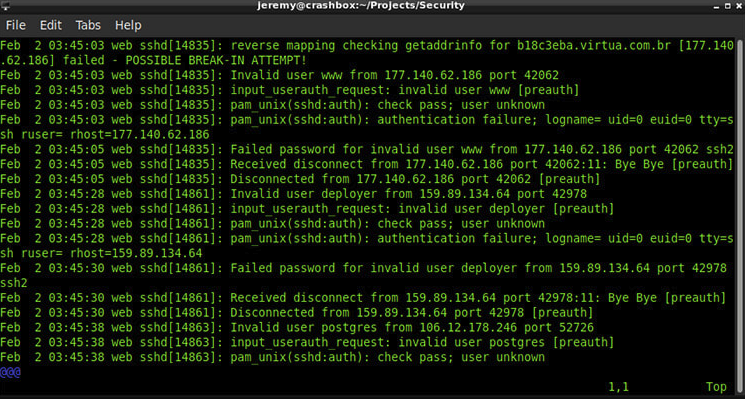
对于301,327行,我不太可能手动查看。让我们自动化一点。
获取攻击者的 IP 地址
我想从这个文件中提取攻击者的 IP 地址,这样我就可以阻止他们。
我开始胡乱使用 Linux 命令,直到我想出了这个脚本。
它所做的非常简单,它将寻找这些字符串:
declare -a badstrings=("Failed password for invalid user"
"input_userauth_request: invalid user"
"pam_unix(sshd:auth): check pass; user unknown"
"input_userauth_request: invalid user"
"does not map back to the address"
"pam_unix(sshd:auth): authentication failure"
"input_userauth_request: invalid user"
"reverse mapping checking getaddrinfo for"
"input_userauth_request: invalid user"
)
这些是标识失败攻击日志的字符串。 如果他们输入了错误的用户名或者尝试了其他形式的攻击,它就会有一个这样的字符串。
因此,我们循环遍历该列表并搜索这些字符串,然后从字符串所在的行中提取 IP 地址。
cat /var/log/secure | grep "$i" | grep -E -o "([0-9]{1,3}[\.]){3}[0-9]{1,3}" | awk '{print $0}' | sort | uniq >> "temp.txt"
然后将 IP 转储到 temp.txt 文件中。 它将对我的“坏字符串”列表中的所有消息执行此操作。
那个文本文件中有很多重复的文件,所以我删除了重复的文件,只把唯一的 ip 放到一个文件中:
# grab unique ips from temp and put them in a file
cat "temp.txt" | sort | uniq > "badguyips.txt"
# remove the temp file
rm "temp.txt"
酷,现在我有一个 IP 地址列表可以使用了。
哎呀,我这里有1141个 IP 地址。
阻止他们
现在我要阻止这些 IP 地址。 因为我正在运行 iptables,我可以用这个简单的脚本删除它们:
#!/bin/bash
input="badguyips.txt"
while IFS= read -r line
do
iptables -A INPUT -s $line -j DROP
done < "$input"
service iptables save
酷,现在攻击者阻止了我的服务器。
然后我开始好奇,这些攻击到底是从哪里来的?
获取他们的位置数据
因为我有一个 IP 地址列表,我想我应该在 Maxmind 这样的数据库中运行它们来查找一些位置信息。 所以我就这么做了。
我编写了一个名为“寻找坏人”的戈朗程序,该程序将遍历 IP 地址的文本文件,查找它们的位置信息,然后将其写入一系列文本文件中。
我根据以下内容写出了这些地点:
Continent 欧洲大陆
Countries 国家
Cities 城市
Subdivisions of Cities 城市细分
我想知道这些攻击来自哪里,并分享这些信息。 所以我运行了我构建的程序,现在有了一些有用的位置信息列表:

大陆
现在我想看一下
那就有问题了,有一些副本。
 我可以运行一个快速命令,得到唯一的值:
我可以运行一个快速命令,得到唯一的值:
cat continents | sort | uniq
如果你曾经看过一个地球仪,结果应该不会令人惊讶:
但是我想看看每个大陆有多少袭击。 所以我请我的老朋友 uniq 帮忙:
awk -F '\n' '{print $0}' continents.txt | sort | uniq -c
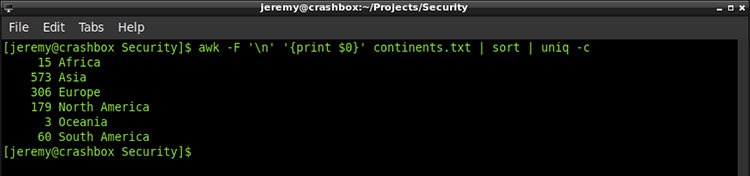 很不错,对吧? 因此,我将删除前导空格,在计数之后插入一个逗号,并将其放入一个文本文件中。
很不错,对吧? 因此,我将删除前导空格,在计数之后插入一个逗号,并将其放入一个文本文件中。
awk -F '\n' '{print $0}' continents.txt | sort | uniq -c | awk '{$1=$1};1' | sed -r 's/\s+/,/' > contintent-totals.txt
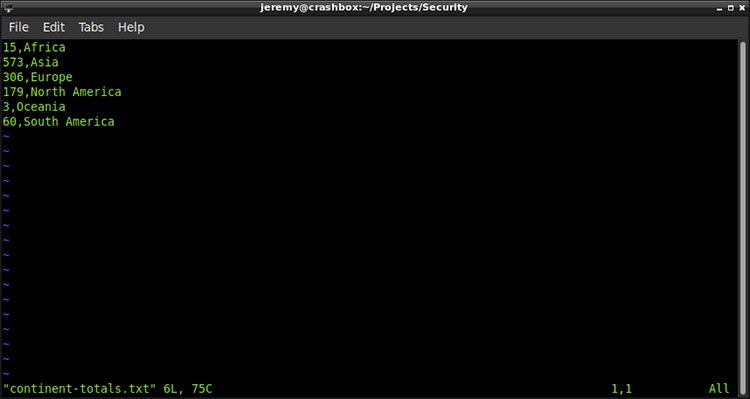 现在我可以把它放到谷歌表格里了。
现在我可以把它放到谷歌表格里了。
看看这个漂亮的图表:
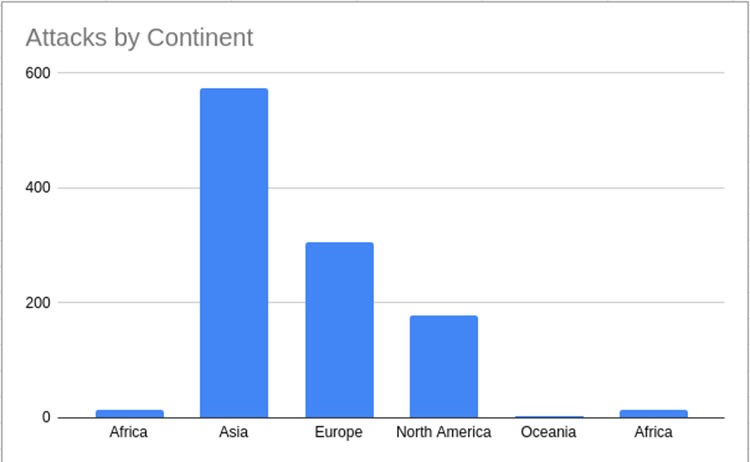
这是我在其他地点(国家、城市、地区)重复的过程,所以我不会重复。 以下是我的研究结果:
国家
以下是排名前十的攻击者来自的国家:
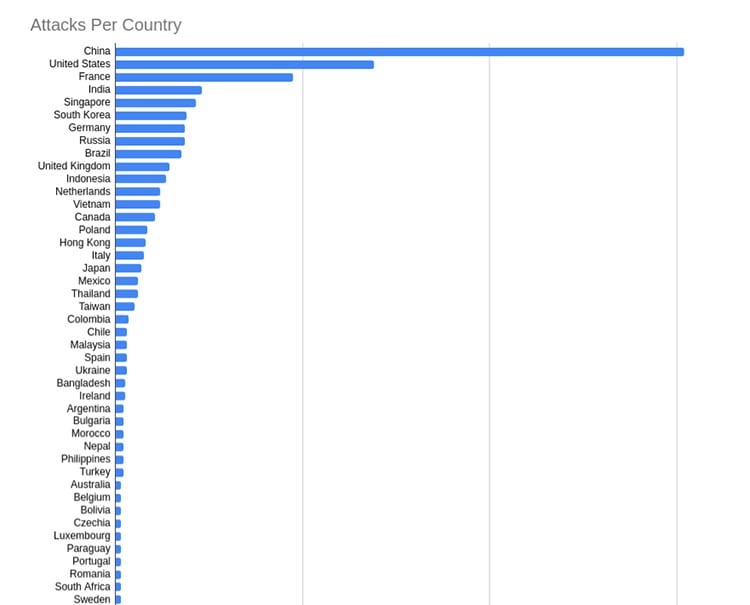
China (304) 中国(304) United States (138) 美国(138个) France (95) 法国(95) India (46) 印度(46) Singapore (43) 新加坡(43) South Korea (38) 韩国(38) Germany (37) 德国(37) Russia (37) 俄罗斯(37) Brazil (35) 巴西(35) United Kingdom (29) 英国(29)
城市
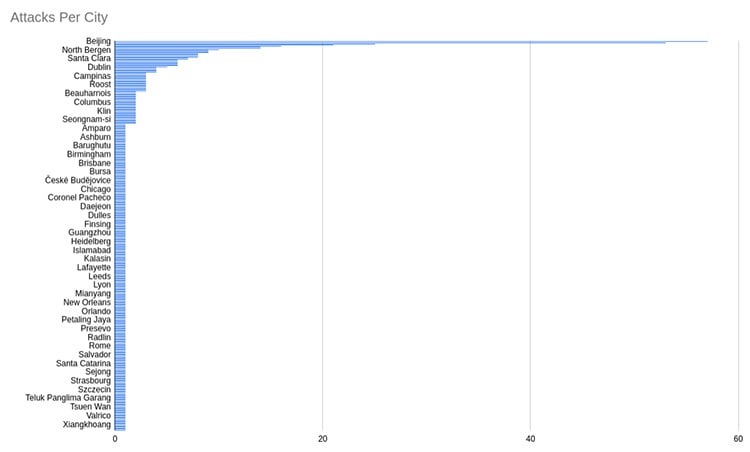 每个城市的攻击更加集中。
每个城市的攻击更加集中。
Beijing (57) 北京(57) Shanghai (53) 上海(53) Hefei (25) 合肥(25岁) Amsterdam (21) 阿姆斯特丹(21) Bengaluru (16) 班加罗尔(16) London (14) 伦敦(14) Xinpu (14) 新浦(14岁) Clifton (10) 克利夫顿(10) North Bergen (9) 北卑尔根(9) But still pretty interesting.
但还是很有意思。
分区
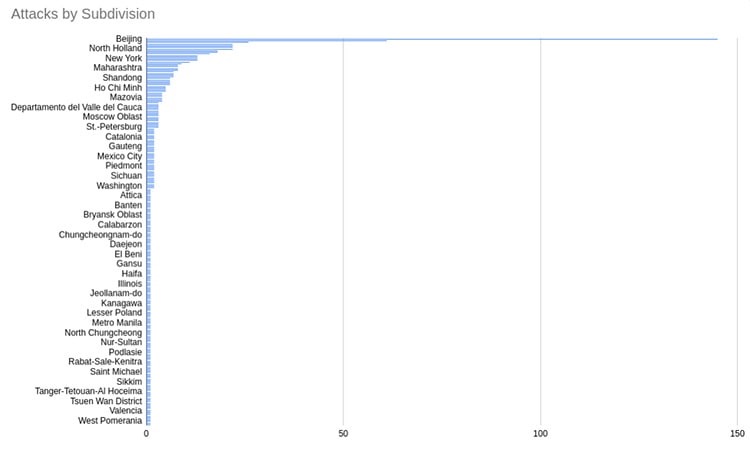
这一点更加重要。 但是它更深入一些。 以下是排名前10的细分攻击者:
Beijing (145) 北京(145) Shanghai (61) 上海(61) Anhui (26) 安徽(26) England (22) 英格兰(22) Jiangsu (22) 江苏(22) New Jersey (22) 新泽西州(22) North Holland (22) 北荷兰(22) California (18) 加利福尼亚州(18个) Sao Paulo (18) 圣保罗(18) Karnataka (16)
小结
伟大的事情总是来自好奇心。 我很好奇还有什么其他类型的模式和数据可以从中提取,所以我将继续尝试和使用它。
如果你决定你想为你的网站做这些事情,试试这些步骤,如果你需要任何帮助,让我知道。