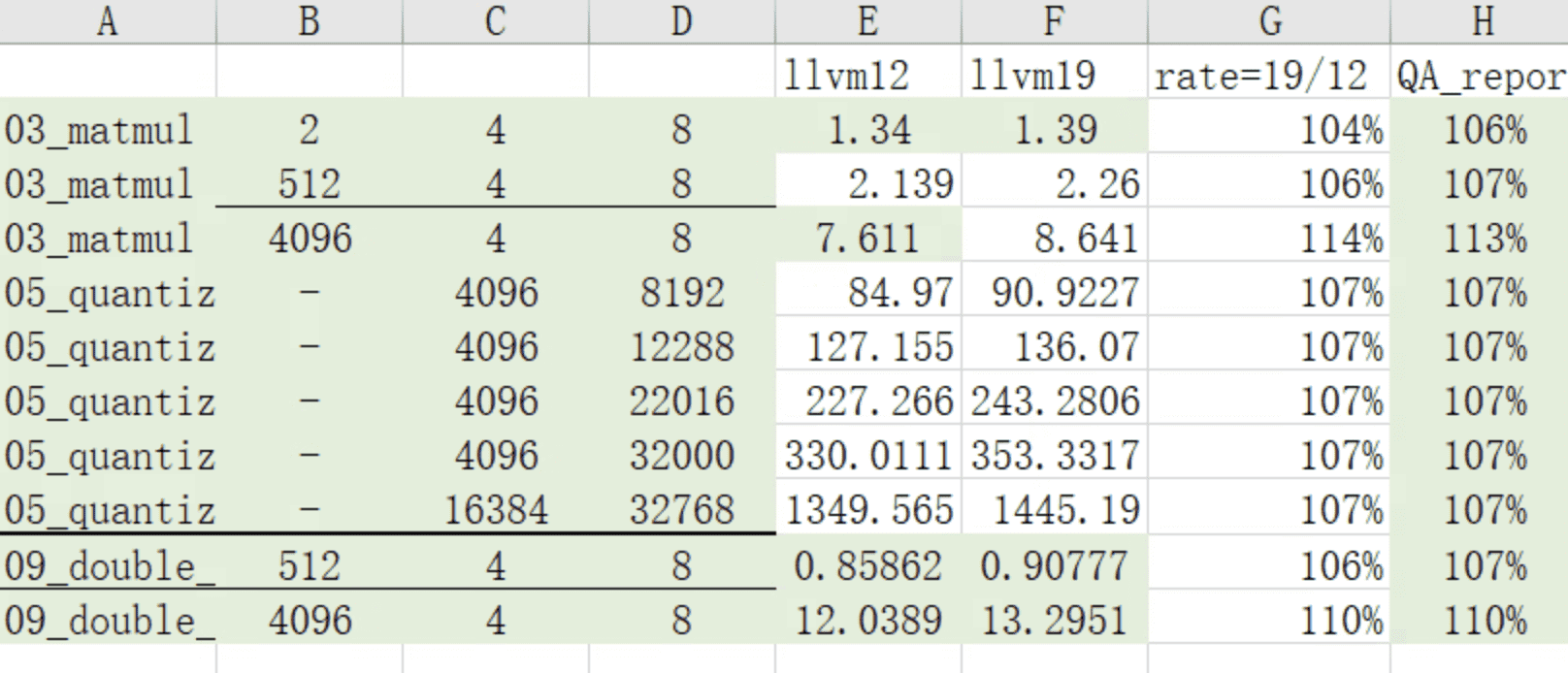
问题: 在bitsandbytes里面,从llvm12升级到llvm19之后,部分性能下降。 matmul和double_quant,部分case性能下降6%~13%。 matmul的最后一个下降,13%
{kind=link}
思路是: 先复现这个问题,可以H列QA测试的结果保持一致。性能确实有回退。 先用内部工具,分析是哪一个kernel的占比耗时比较高。
这个工具可以参考cuda profiler之类的工具,可以统计到每一个kernel执行的cycle值。
同一个名称的 mangled 名称是一样的,mangled是带了参数的,所以不怕有不同参数的kernel 函数了。
通过AI,直接生成一个python脚本,来分析这个json文件,大文件,记得用ijson,不是json。
得到的数据,然后按照cycle的降序排序。
这个方法内部同事把这个定义为找hot kernel。
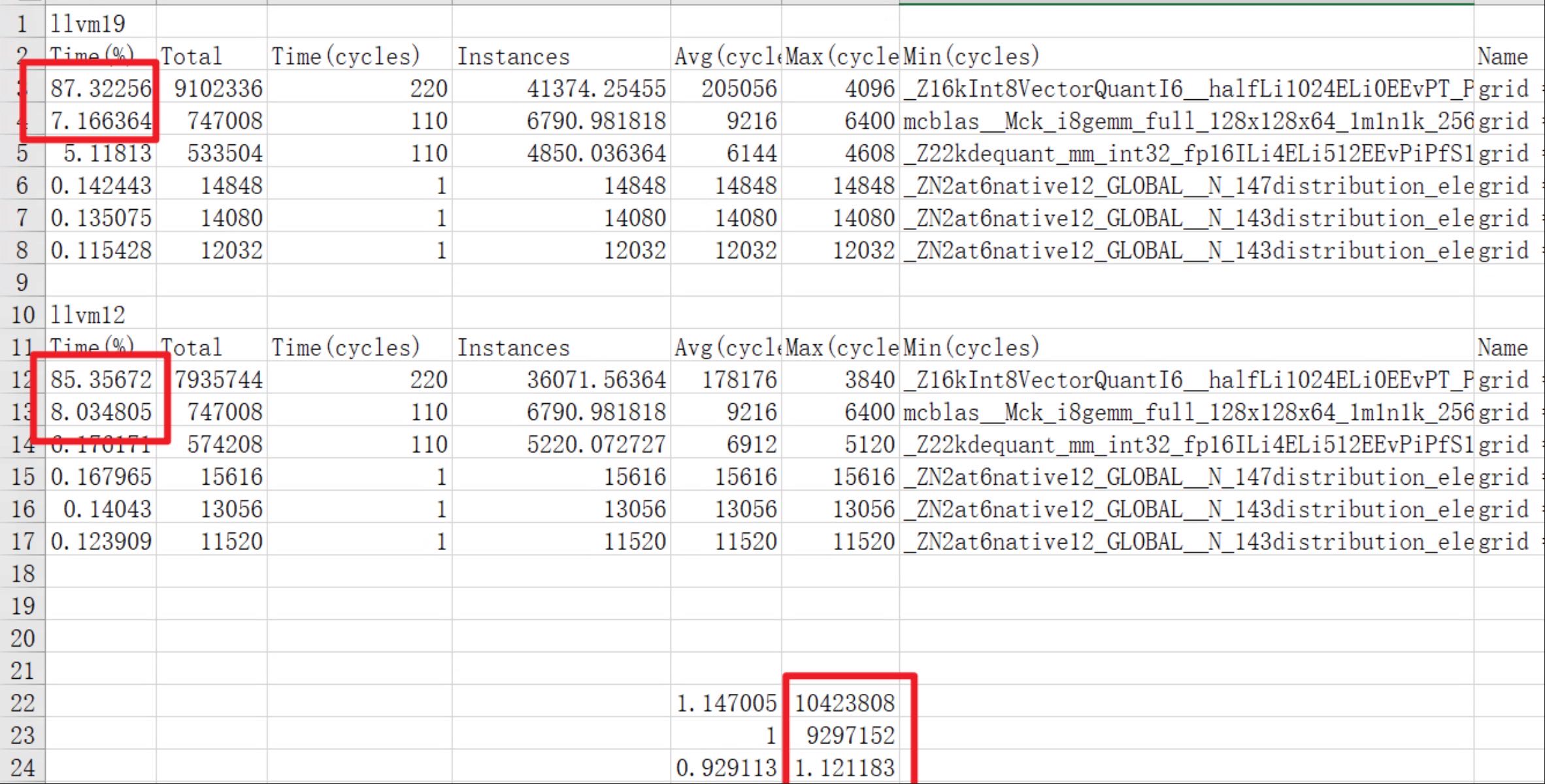 可以看到这个回退的结果,里面其中一个kernel占比llvm12和19都是87%左右,挺大的,在看具体icycle值对比,也是回退和实际一致。
可以看到这个回退的结果,里面其中一个kernel占比llvm12和19都是87%左右,挺大的,在看具体icycle值对比,也是回退和实际一致。
问题找到了,可以下结论了。就是这个kernel 主要导致了性能回退的原因。
那就开始深入分析kernel了,通过c++filt,可以看到这个kernel具体的名称,参数是什么?
找到kernel name之后,在对应的测试集,或者是模型里面,找到对应的device函数名称。
通过rg,或者grep 。找到这个函数在哪里。
找到之后, https://github.com/bitsandbytes-foundation/bitsandbytes/blob/main/csrc/kernels.cu:1766
开源的工具,在1766行。
是一个模板,看他实例化的地方, https://github.com/bitsandbytes-foundation/bitsandbytes/blob/main/csrc/ops.cu: 446行的地方,有2个是实例化,但是参数对的上的之后一个。
这个就好办了。
先make的时候 verbose=1,打印出编译命令,然后修改这个cu文件,只保留这么一个实例化, 这样就搞了一个mini-case来复现问题。
然后对比汇编。
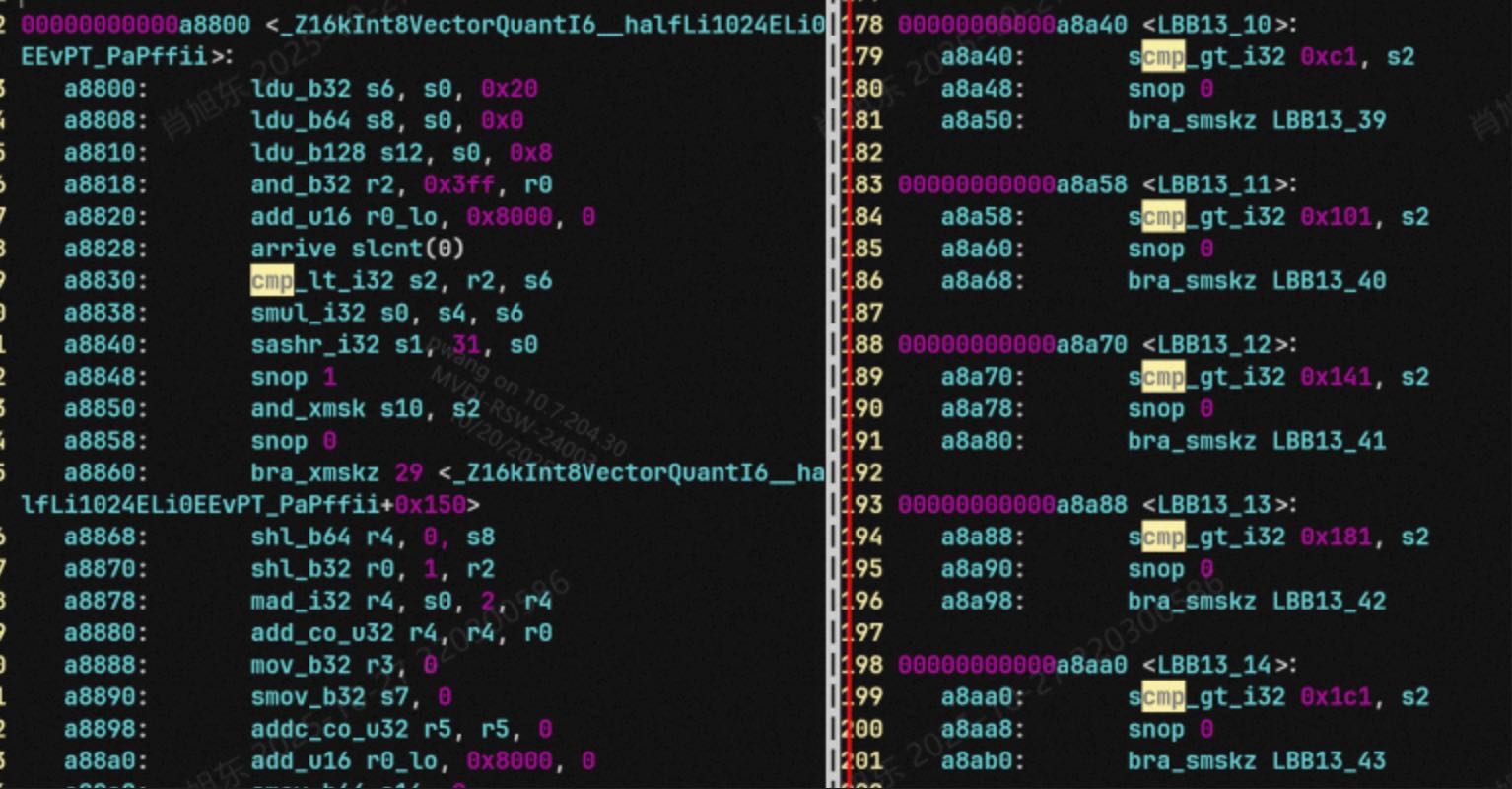
可以看到llvm12的bb块多了很多,llvm19少了很多。
可能的原因就是bb块多了之后,走到一个有endk的bb块,直接就跳出了。所以性能好。
那就分析这个bb块是怎么来的,llvm19的bb块是怎么被优化没的。
首先,通过-print-after-all, -filter-function-print, 找到只包含这个kernel的情况,获取到IR文件。
用AI写一个python脚本,分析下这个只包含这个函数的bb块,变化情况。
初步找到是inline一个pass导致的,
这个就是不优化的,地方,说明是从其他子函数带过来的bb块。需要从子函数来分析。
统计下print-after-inline后的bb情况变化, 可以看到llvm19是很高的。
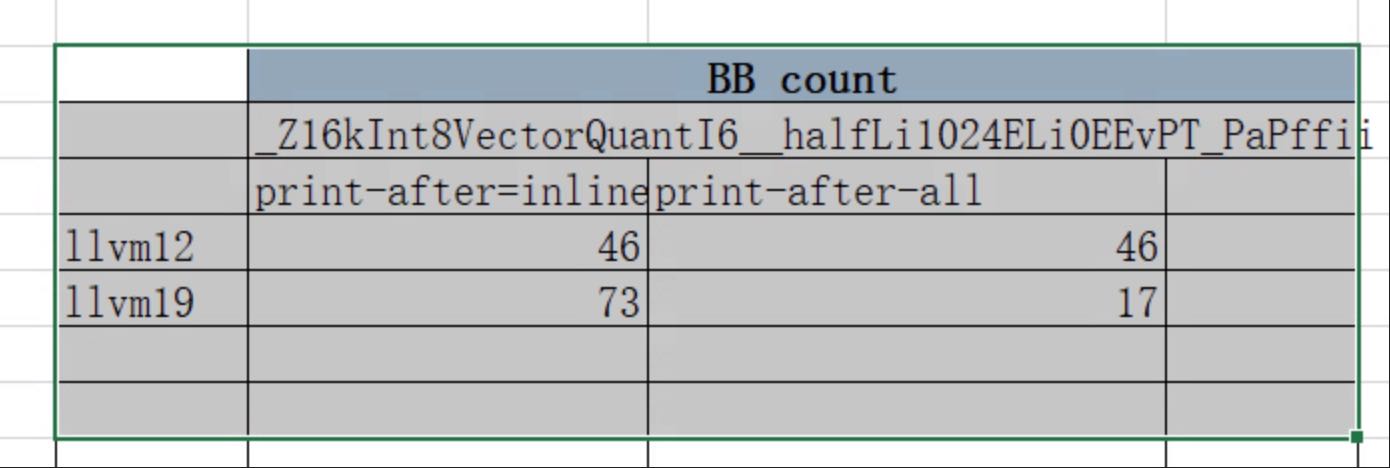
方向对了。
那在看print-after-all, 就看这个bb块什么时候减少了。
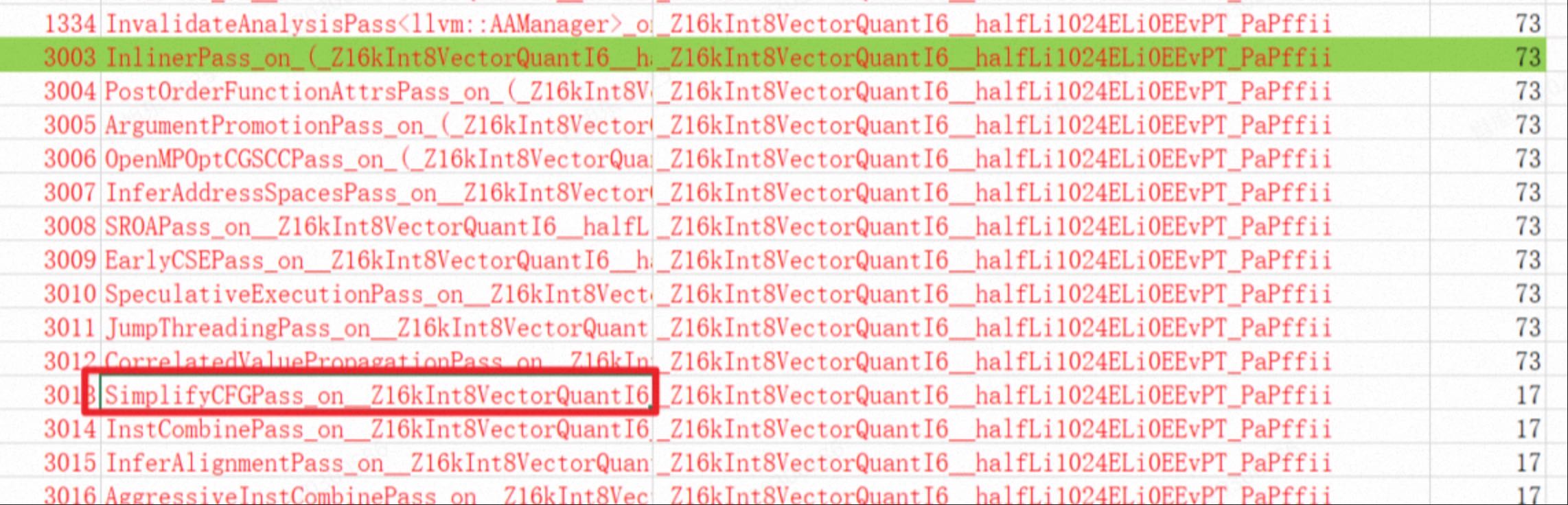
可以看到前面都是73个bb块,后面就变成了17个, 就是这个simpfyCFG pass导致的,通过查看passBuilder pipeline这个pass。 找到对应的代码,主要上下的pass需要对应上,然后直接注释这个代码。
先看看汇编有变化没?有了
然后注释代码,看看性能怎么样? 正常了。
那就开始添加一个编译选项,专门控制这个地方,提供给bitsandbytes来使用。
ok,梳理代码,提交,合并到dev,等待验证结果。